Audio processing: Following the brain's lead

When designed to process sound based on familiar patterns, sound recognition by computers becomes more robust.
Computers, machines and even smart phones can process sounds and audio signals with apparent ease, but they all require significant computing power. Researchers from the A*STAR Institute for Infocomm Research in Singapore have proposed a way to improve computer audio processing by applying lessons inspired from the way the brain processes sounds1.
"The method proposed in our study may not only contribute to a better understanding of the mechanisms by which the biological acoustic systems operate, but also enhance both the effectiveness and efficiency of audio processing," comments Huajin Tang, an electrical engineer from the research team.
When listening to someone speaking in a quiet room, it is easy to identify the speaker and understand their words. While the same words spoken in a loud bar are more difficult to process, our brain is still capable of distinguishing the voice of the speaker from the background noise. Computers, on the other hand, still have considerable problems identifying complex sounds from a noisy background; even smart phones must send audio signals to a powerful centralized server for processing.
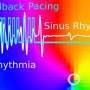
Considerable computing power at the server is required because the computer continuously processes the entire spectrum of human audio frequencies. The brain, however, analyzes information more selectively: it processes audio patterns localized in time and frequency (see image). When someone speaks with a deep voice, for example, the brain dispenses with analyzing high-pitched sounds. So when a speaker in a loud bar stops talking, the brain stops trying to catch and process the sounds that form his words.
Tang and his team emulated the brain's sound-recognition strategy by identifying key points in the audio spectrum of a sound. These points could be characteristic frequencies in a voice or repeating patterns, such as those of an alarm bell. They analyzed the signal in more detail around these key points only, looking for familiar audio frequencies as well as time patterns. This analysis enabled a robust extraction of matching signals when a noise was present. To improve the detection over time, the researchers fed matching frequency patterns into a neurological algorithm that mimics the way the brain learns through the repetition of known patterns.
In computer experiments, the algorithm successfully processed known target signals, even in the presence of noise. Expanding this approach, says Tang, "could lead to a greater understanding of the way the brain processes sound; and, beyond that, it could also include touch, vision and other senses."
The A*STAR-affiliated researchers contributing to this research are from the Institute for Infocomm Research
More information: Dennis, J., Yu, Q., Tang, H., Tran, H. D. & Li, H. Temporal coding of local spectrogram features for robust sound recognition. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 26–31 May 2013. ieeexplore.ieee.org/xpl/articl … =6637759&refinements%3D4280436187%26sortType%3Dasc_p_Sequence%26filter%3DAND%28p_IS_Number%3A6637585%29