Team develops tool to better classify tumor cells for personalized cancer treatments
A new statistical model developed by a research team at Worcester Polytechnic Institute (WPI) may enable physicians to create personalized cancer treatments for patients based on the specific genetic mutations found in their tumors.
Just as cancer is not a single disease, but a collection of many diseases, an individual tumor is not likely to be comprised of just one type of cancer cell. In fact, the genetic mutations that lead to cancer in the first place also often result in tumors with a mix of cancer cell subtypes.
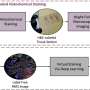
The WPI team developed a new statistical model that uses an advanced algorithm to identify these multiple genetic subtypes in solid tumors by analyzing gene expression data from a small biopsy sample. The results can help shape more effective cancer treatments and also guide future research. Details of the new model are reported in the paper "GLAD: A mixed-membership model for heterogeneous tumor subtype classification" published by the journal Bioinformatics.
"Many of the statistical models used today to classify tumors are limited by an 'all-or-none' approach," said Patrick Flaherty, PhD., assistant professor of biomedical engineering at WPI and senior author of the new paper. "In other words, they classify only a single, dominant cancer cell subtype in a tumor, but that can be misleading. A drug that can target one subtype of cancer cells may have no effect on another subtype. So we set out to develop a model that could more accurately predict the multiple fractions of cancer cell subtypes in a tumor."
Cancer cells proliferate unchecked because genetic mutations enable them to grow in an abnormal way and evade the body's natural defenses. As a tumor grows, those cancer cells multiply and evolve, forming clusters of different subtypes. Each subtype can be identified by the unique pattern of the products produced by their genes. With the cost of DNA sequencing tests that produce this type of data decreasing, the need for statistical tools to handle the flood of data and create relevant information that physicians can use in real time increases.
"Because clinical labs can now sequence the genomes of a patient's cancer cells, prognosis and treatment is becoming a big data problem," Flaherty said. "Our lab is focused on extracting actionable information from big data sets so physicians and patients can make better decisions."
As reported in their paper, Flaherty's team developed a new model called GLAD (for Gaussian, Laplace, and Dirichlet, the statistical distributions in the model). They first tested GLAD on a simulated data set built to resemble gene expression patterns of a tumor with two subtypes of cancer cells. The model identified the correct fractions of the two subtypes. Next, GLAD used gene expression data to accurately determine the percentages of rat lung, brain, and liver cells in a sample with known proportions of those cells. Finally, GLAD was applied to gene expression data from 202 glioblastoma (human brain tumor) samples obtained from the Cancer Genome Atlas Project. Glioblastoma tumors are thought to have four subtypes of cells, and GLAD accurately predicted the fraction of each.
Looking ahead, Flaherty is exploring collaborations with clinical partners who are treating breast cancer patients. The hope is to apply the GLAD model to gene expression data from patient biopsies over time and see how the results correlate with the patients' outcomes and the chemotherapies used. Flaherty has also made the complete GLAD model available for downloading by colleagues around the world to test and apply in their research.
"We are looking forward to the clinical testing and are hopeful that in the coming years the model will be helpful for physicians as they treat patients with combinations of therapies that are effective against an entire tumor," Flaherty said