Credit: CC0 Public Domain
A new study in the Journal of Biomedical Informatics uses machine learning on unlabeled electronic health record (EHR) data to shed light on the emergence of cardiovascular disease (CVD).
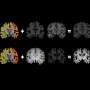
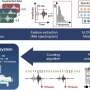
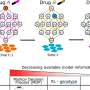
The study hinges on automated patient phenotyping (if eye color is a trait, blue eyes are a phenotype) and ample longitudinal data. Juan Zhao, Ph.D., Wei-Qi Wei, MD, Ph.D., and colleagues gathered 12,380 de-identified patient records that reached back at least 10 years prior to a CVD diagnosis. An automated scan found some 1,068 distinct patient phenotypes in this dataset.
Aided by a technique called tensor decomposition, unsupervised machine learning revealed the long-term emergence of 14 distinct CVD patient subtypes. Across the six most prevalent subtypes the risk of heart attack was markedly different, indicating the scan had struck meaningful distinctions.
Certain phenotypes that came forth prominently in the scan—urinary infection, vitamin D deficiency, depression—would appear to challenge current understanding of the routes by which CVD emerges.
More information: Juan Zhao et al. Detecting time-evolving phenotypic topics via tensor factorization on electronic health records: Cardiovascular disease case study, Journal of Biomedical Informatics (2019). DOI: 10.1016/j.jbi.2019.103270
Provided by Vanderbilt University