Credit: CC0 Public Domain
Humans can effortlessly recognize and react to natural sounds and are especially tuned to speech. There have been several studies aimed to localize and understand the speech-specific parts of the brain, but as the same brain areas are mostly active for all sounds, it has remained unclear whether or not the brain has unique processes for speech processing, and how it performs these processes. One of the main challenges has been to describe how the brain matches highly variable acoustic signals to linguistic representations when there is no one-to-one correspondence between the two—how the brain identifies the same words spoken by very different speakers and dialects as the same.
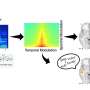
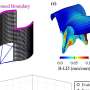
For this latest study, the researchers, led by Professor Riitta Salmelin, decoded and reconstructed spoken words from millisecond-scale brain recordings in 16 healthy Finnish volunteers. They adopted the novel approach of using the natural acoustic variability of a large variety of sounds (words spoken by different speakers, environmental sounds from many categories) and mapping them to magnetoencephalography (MEG) data using physiologically-inspired machine-learning models. These types of models, with time-resolved and time-averaged representations of the sounds, have been used in brain research before. The novel, scalable formulation by co-lead author Ali Faisal allowed for applying such models to whole-brain recordings, and this study is the first to compare the same models for speech and other sounds.
Aalto researcher and lead author Anni Nora says, 'We discovered that time-locking of the cortical activation to the unfolding speech input is crucial for the encoding of speech. When we hear a word, e.g. "cat", our brain has to follow it very accurately in time to be able to understand its meaning'.
As a contrast, time-locking was not highlighted in cortical processing of non-speech environmental sounds that conveyed the same meanings as the spoken words, such as music or laughter. Instead, time-averaged analysis is sufficient to reach their meanings. 'This means that the same representations (how a cat looks like, what it does, how it feels etc.) are accessed by the brain also when you hear a cat meowing, but the sound itself is analyzed as a whole, without need for similar time-locking of brain activation', Nora explains.
Time-locked encoding was also observed for meaningless new words. However, even responses to human-made non-speech sounds such as laughing didn't show improved decoding with the dynamic time-locked mechanism and were better reconstructed using a time-averaged model, suggesting that time-locked encoding is special for sounds identified as speech.
Results indicate that brain responses follow speech with especially high temporal fidelity
The current results suggest that, in humans, a special time-locked encoding mechanism might have evolved for speech. Based on other studies, this processing mechanism seems to be tuned to the native language with extensive exposure to the language environment during early development.
The present finding of time-locked encoding, especially for speech, deepens the understanding of the computations required for mapping between acoustic and linguistic representations (from sounds to words). The current findings raise the question of what specific aspects within sounds are crucial for cueing the brain into using this special mode of encoding. To investigate this further, the researchers aim next to use real-life like auditory environments such as overlapping environmental sounds and speech.'Future studies should also determine whether similar time-locking might be observed with specialization in processing other sounds through experience, e.g. for instrumental sounds in musicians', Nora says
Future work could investigate the contribution of different properties within speech acoustics and the possible effect of an experimental task to boost the use of time-locked or time-averaged mode in sound processing. These machine learning models could also be very useful when applied to clinical groups, such as investigating individuals with impaired speech processing.
More information: A. Nora et al, Dynamic time-locking mechanism in the cortical representation of spoken words, eNeuro (2020). DOI: 10.1523/ENEURO.0475-19.2020
Provided by Aalto University