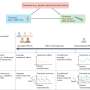
Researchers at The University of Tokyo use the mathematics of adaptive learning and artificial intelligence to describe how T helper cells adjust the response of the vertebrate immune system, which may lead to new vaccines and treatments for infections Credit: Institute of Industrial Science, University of Tokyo
Scientists from the Institute of Industrial Science at The University of Tokyo demonstrated how the adaptive immune system uses a method similar to reinforcement learning to control the immune reaction to repeat infections. This work may lead to significant improvements in vaccine development and interventions to boost the immune system.
In the human body, the adaptive immune system fights germs by remembering previous infections so it can respond quickly if the same pathogens return. This complex process depends on the cooperation of many cell types. Among these are T helpers, which assist by coordinating the response of other parts of the immune system—called effector cells—such as T killer and B cells. When an invading pathogen is detected, antigen presenting cells bring an identifying piece of the germ to a T cell. Certain T cells become activated and multiply many times in a process known as clonal selection. These clones then marshal a particular set of effector cells to battle the germs. Although the immune system has been extensively studied for decades, the 'algorithm' used by T cells to optimize the response to threats is largely unknown.
Now, scientists at The University of Tokyo have used an artificial intelligence framework to show that the number of T helpers act like the 'hidden layer' between inputs and outputs in an artificial neural network commonly used in adaptive learning. In this case, the antigens presented are the inputs, and the responding effector immune cells are the output.
"Just as a neural network can be trained in machine learning, we believe the immune network can reflect associations between antigen patterns and the effective responses to pathogens," first author Takuya Kato says.
The main difference between the adaptive immune system compared with computer machine learning is that only the number of T helper cells of each type can be varied, as opposed to the connection weights between nodes in each layer. The team used computer simulations to predict the distribution of T cell abundances after undergoing adaptive learning. These values were found to agree with experimental data based on the genetic sequencing of actual T helper cells.
"Our theoretical framework may completely change our understanding of adaptive immunity as a real learning system," says co-author Tetsuya Kobayashi. "This research can shed light on other complex adaptive systems, as well as ways to optimize vaccines to evoke a stronger immune response."
More information: Takuya Kato et al, Understanding adaptive immune system as reinforcement learning, Physical Review Research (2021). DOI: 10.1103/PhysRevResearch.3.013222
Provided by University of Tokyo