Validating digital tools for remote clinical research
A team of scientists from Cambridge Cognition and the University of Bristol have been developing digital assessments for remote clinical research.
Researchers are increasingly keen on carrying out psychological research remotely, so they can study cognition and behavior when and where they naturally occur.
Remote methods also improve accessibility as participants are not required to travel to testing locations or meet face-to-face, an especially important consideration during the SARS-CoV-2 pandemic. However, it is still unclear how best to validate digital tools for remote clinical research.
Experts have been looking at various approaches to developing digital assessments for remote clinical research, which they discuss in a paper published in the Journal of Medical Internet Research.
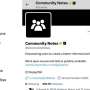
When creating any new psychological assessment, it is important that scientists ensure that the assessment accurately measures the concept, behavior, or symptom that it intends to gauge. Part of this validation process is ruling out the possibility that changes to the outcome of interest are the result of external influences. Traditionally, when assessments are delivered in the laboratory, researchers ensure that an assessment is reliable by administering the assessment to the same person, in the same environment, at the same time of day on two different days produced two similar scores. Researchers decide that an assessment is valid if administering the assessment alongside a gold-standard assessment to the same person under controlled conditions produces scores that are consistent with each another.
"If an individual does not score similarly on an assessment taken at different time points, it does not necessarily mean that the assessment is unreliable," said Dr. Francesca Cormack, study author and Director of Research & Innovation at Cambridge Cognition. "For example, mood can vary considerably as a function of time. Therefore, when measuring mood, or a phenomenon that is sensitive to mood, there may be considerable difference in measurements taken at different time points. Similarly, demonstrating the validity of an assessment in a controlled laboratory environment does not necessarily tell us about its validity in the real world."
To increase the ecological validity such as generalizability to real life situations of research findings, web-based data collection has increased in popularity over the years. As long as participants can access a computer and internet connection and can spare at least five minutes, they are able to complete many types of cognitive tasks or questionnaires outside of the laboratory. Because researchers have less control over the environment in which participants complete web-based assessments, researchers have compared performance on the same assessments administered on the web and in the laboratory to validate web-based assessments.
To capture more granular changes in behavior over time and across settings, brief assessments (those that take a couple of minutes or seconds to complete) can be delivered on devices that individuals carry on their person including smartphones and smartwatches. However, it is more challenging to systematically evaluate web-based assessments that are administered in this way, as the research environment (ie time and space) is uncontrolled. Although it is possible to compare outcomes from a high-frequency field assessment to outcomes from a low-frequency laboratory assessment, scientists must consider that the contexts in which the data are being collected are very distinct from one another.
Therefore, the authors propose that a controlled environment may not be necessary, nor appropriate, to validate such flexible data collection tools. An alternative is to compare outcomes from a high-frequency field assessment to outcomes from another high-frequency field assessment, both administered in the same temporal and spatial context. Dr. Gareth Griffith of Bristol's Medical School said: "In the absence of controlled laboratory conditions, researchers must instead rely on collecting information on the respondent context, and accounting for this in further analyses."
"Using brief assessments allows researchers to collect data frequently, perhaps a couple of times per week or per day, without causing too much burden to participants," said study author and Senior Research Associate at the University of Bristol's School of Psychological Science, Dr. Jennifer Ferrar. "However, this will depend on the specific assessment and the population being studied. Someone with a medical condition might have a much lower threshold for the number of assessments they can comfortably complete than a healthy control might have. This is not only an ethical issue but can negatively impact participant engagement and data quality. Ideally, we want the assessments to be as brief as possible but removing components of the assessment might weaken its validity. These are important tools, but as with any tool, we need to ensure that they are used appropriately."
More information: 'Developing Digital Tools for Remote Clinical Research: How to Evaluate the Validity and Practicality of Active Assessments in Field Settings' in Journal of Medical Internet Research by J Ferrar et al.