Large language models (LLMs) like ChatGPT can respond to patient-written ophthalmology questions and usually generate appropriate responses, according to a study published online Aug. 22 in JAMA Network Open.
Isaac A. Bernstein, from Stanford University in California, and colleagues examined the quality of ophthalmology advice generated by an LLM chatbot compared with ophthalmologist-written advice. The study used deidentified data from an online medical forum, in which patient questions received responses written by ophthalmologists. A masked panel of eight board-certified ophthalmologists were asked to differentiate between answers generated by the ChatGPT chatbot and answers from ophthalmologists.
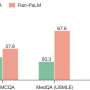
Two hundred pairs of user questions and answers were assessed. The researchers found that the mean accuracy was 61.3 percent for differentiating artificial intelligence (AI) and human responses. Of 800 assessments of chatbot-written answers, 21.0 and 64.6 percent were marked as human-written and AI-written, respectively. Chatbot answers were more often rated as probably or definitely written by AI compared with human answers. The likelihood of chatbot answers containing incorrect or inappropriate material and likelihood of harm was comparable with human answers.
"We intend for this study to catalyze more extensive and nuanced dialogue and joint efforts surrounding the use of LLMs in ophthalmology among various health care stakeholders, including patients, clinicians, researchers, and policy makers," the authors write. "The primary goal is to prudently leverage these early research findings to shape the responsible implementation of LLMs in the field of ophthalmology."
More information: Isaac A. Bernstein et al, Comparison of Ophthalmologist and Large Language Model Chatbot Responses to Online Patient Eye Care Questions, JAMA Network Open (2023). DOI: 10.1001/jamanetworkopen.2023.30320
Journal information: JAMA Network Open
Copyright © 2023 HealthDay. All rights reserved.