Researchers find brain area that integrates speech's rhythms

Duke and MIT scientists have discovered an area of the brain that is sensitive to the timing of speech, a crucial element of spoken language.
Timing matters to the structure of human speech. For example, phonemes are the shortest, most basic unit of speech and last an average of 30 to 60 milliseconds. By comparison, syllables take longer: 200 to 300 milliseconds. Most whole words are longer still.
In order to understand speech, the brain needs to somehow integrate this rapidly evolving information.
The auditory system, like other sensory systems, likely takes shortcuts to cope with the onslaught of information—by, for example, sampling information in chunks similar in length to that of an average consonant or syllable, says study co-author Tobias Overath, an assistant research professor of psychology and neuroscience at Duke. The other corresponding author is Josh McDermott from MIT.
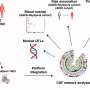
In a study appearing May 18 in the journal Nature Neuroscience, Overath and his collaborators cut recordings of foreign speech into short chunks ranging from 30 to 960 milliseconds in length, and then reassembled the pieces using a novel algorithm to create new sounds that the authors call 'speech quilts'.
The shorter the pieces of the resulting speech quilts, the greater the disruption was to the original structure of the speech.
To measure the activity of neurons in real time, the scientists played speech quilts to study participants while scanning their brains in a functional magnetic resonance imaging machine. The team hypothesized that brain areas involved in speech processing would show larger responses to speech quilts made up of longer segments.
Indeed, a region of the brain called the superior temporal sulcus (STS) became highly active during the 480- and 960-millisecond quilts compared with the 30-millisecond quilts.
In contrast, other areas of the brain involved in processing sound did not change their response as a result of the differences in the sound quilts.
"That was pretty exciting. We knew we were onto something," said Overath, who is a member of the Duke Institute for Brain Sciences
The superior temporal sulcus is known to integrate auditory and other sensory information. But no one has shown that the STS is sensitive to time structures in speech.
To rule out other explanations for the activation of the STS, the researchers tested numerous control sounds they created to mimic speech. One of the synthetic sounds they created shared the frequency of speech but lacked its rhythms. Another removed all the pitch from the speech. A third used environmental sounds.
They quilted each of these control stimuli, chopping them up in either 30- or 960-millisecond pieces and stitching them back together, before playing them to participants. The STS didn't seem responsive to the quilting manipulation when it was applied to these control sounds.
"We really went to great lengths to be certain that the effect we were seeing in STS was due to speech-specific processing and not due to some other explanation, for example, pitch in the sound or it being a natural sound as opposed to some computer-generated sound," Overath said.
The group plans to study whether the response in STS is similar for foreign speech that is phonetically much different than English, such as Mandarin, or quilts of familiar speech that is intelligible and has meaning. For familiar speech they might see stronger activation on the left side of the brain, which is thought to be dominant in processing language.
More information: The cortical analysis of speech-specific temporal structure revealed by responses to sound quilts, Nature Neuroscience, DOI: 10.1038/nn.4021