Multi-algorithm approach helps deliver personalized medicine for cancer patients

Today, machine learning, artificial intelligence, and algorithmic advancements made by research scientists and engineers are driving more targeted medical therapies through the power of prediction. The ability to rapidly analyze large amounts of complex data has clinicians closer to providing individualized treatments for patients, with an aim to create better outcomes through more proactive, personalized medicine and care.
"In medicine, we need to be able to make predictions," said John F. McDonald, professor in the School of Biological Sciences and director of the Integrated Cancer Research Center in the Petit Institute for Bioengineering and Bioscience at the Georgia Institute of Technology. One way is through understanding cause and reflect relationships, like a cancer patient's response to drugs, he explained. The other way is through correlation.
"In analyzing complex datasets in cancer biology, we can use machine learning, which is simply a sophisticated way to look for correlations. The advantage is that computers can look for these correlations in extremely large and complex data sets."
Now, McDonald's team and the Ovarian Cancer Institute are using ensemble-based machine learning algorithms to predict how patients will respond to cancer-fighting drugs with high accuracy rates. The results of their most recent work have been published in the Journal of Oncology Research.
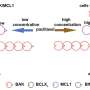
For the study, McDonald and his colleagues developed predictive machine learning-based models for 15 distinct cancer types, using data from 499 independent cell lines provided by the National Cancer Institute. Those models were then validated against a clinical dataset containing seven chemotherapeutic drugs, administered either singularly or in combination, to 23 ovarian cancer patients. The researchers found an overall predictive accuracy of 91%.
"While additional validation will need to be carried out using larger numbers of patients with multiple types of cancer," McDonald noted, "our preliminary finding of 90% accuracy in the prediction of drug responses in ovarian cancer patients is extremely promising and gives me hope that the days of being able to accurately predict optimal cancer drug therapies for individual patients is in sight."
The study was conducted in collaboration with the Ovarian Cancer Institute (OCI) in Atlanta, where McDonald serves as chief research officer. Other authors are Benedict Benigno, MD (OCI founder and chief executive officer, as well as an obstetrician-gynecologist, surgeon, and oncologist); Nick Housley, a postdoctoral researcher in McDonald's Georgia Tech lab; and the paper's lead author, Jai Lanka, an intern with OCI.
The challenges in predicting cancer treatments
The complex nature of cancer makes it a challenging problem when it comes to predicting drug responses, McDonald said. Patients with the same type of cancer will often respond differently to the same therapeutic treatment.
"Part of the problem is that the cancer cell is a highly integrated network of pathways and patient tumors that display the same characteristics clinically may be quite different on the molecular level," he explained.
A major goal of personalized cancer medicine is to accurately predict likely responses to drug treatments based upon genomic profiles of individual patient tumors.
"In our approach, we utilize an ensemble of machine learning methods to build predictive algorithms—based on correlations between gene expression profiles of cancer cell lines or patient tumors with previously observed responses—to a variety of cancer drugs. The future goal is that gene expression profiles of tumor biopsies can be fed into the algorithms, and likely patient responses to different drug therapies can be predicted with high accuracy," said McDonald.
Machine learning is already being applied to the data coming from the genomic profiles of tumor biopsies, but prior to the researchers' work, these methods have typically involved a single algorithmic approach.
McDonald and his team decided to combine several algorithm approaches that use multiple ways to analyze complex data; one even uses a three-dimensional approach. They found using this ensemble-based approach significantly boosted predictive accuracy.
The algorithms the team used have names like Support Vector Machines (SVM), Random Forest classifier (RF), K-Nearest Neighbor classifier (KNN), and Logistic Regression classifier (LR).
"They're all fairly technical, and they're all different computational mathematical approaches, and all of them are looking for correlations," said McDonald. "It's just a question of which one to use, and for different data sets, we find that one model might work better than another."
However, more patient datasets that combine genomic profiles with responses to cancer drugs are needed to advance the research.
"If we want to have a clinical impact, we must validate our models using data from a large number of patients," said McDonald, who added that many datasets are held by pharmaceutical companies who use them in drug development. That data is typically considered proprietary, private information. And although a significant amount of genomic data of cancer patients is generally available, it's not typically correlated with patient responses to drugs.
McDonald is currently talking with medical insurance companies about access to relevant datasets, as well. "It costs insurance companies a significant amount of money to pay for drug treatments that don't work," he noted. Time, medical fees, and ultimately, many lives could be saved by providing researchers with these types of information.
"Right now, a percentage of patients will not respond to a drug, but we don't know that until after six weeks of chemotherapy," said McDonald. "What we hope is that we will soon have tools that can accurately predict the probability of a patient responding to first line therapies—and if they don't respond, to be able to make accurate predictions as to the next drug to be tried."
More information: Results: escires.com/articles/JOR-4-111.pdf