Mining information contained in clinical notes could yield early signs of harmful drug reactions
Mining the records of routine interactions between patients and their care providers can detect drug side effects a couple of years before an official alert from the U.S. Food and Drug Administration, a Stanford University School of Medicine study has found.
The study, led by Nigam Shah, MBBS, PhD, assistant professor of medicine, will be published online April 10 in Nature Clinical Pharmacology and Therapeutics.
This approach is a step forward in mining patient-based information, as opposed to coded insurance reports or drug-specific databases, to improve health-care strategies, said engineering research associate Paea LePendu, PhD, the lead author of the paper. The technique is intended to complement the FDA's Adverse Event Reporting System, which has compiled reports of medication side effects from patients, physicians and pharmaceutical manufacturers since 1968.
Clinical notes include the information a caregiver dictates into a patient's record, such as the patient's symptoms or medical issues. It would also include what a doctor advises or prescribes for the patient.
"If you ask any audience related to health care how much of the clinical knowledge is bundled up in text, you won't get an answer below 70 percent," said Shah. "If 70 to 80 percent of the data is locked up in text notes, we asked ourselves, 'What would be a good way to unlock it?'" Their approach builds on recently published work that developed a gold standard for assessing the performance of data-mining methods.
The information gleaned is intended to support current protocols or clinical experience. Shah and LePendu see their work as a move toward a learning health system, in which we learn from the day-to-day experience and the collective wisdom of the decisions that doctors make when treating patients. They believe health-care providers can apply such data mining to clinical data warehouses to create a new source of evidence—practice-based evidence—for patient care.
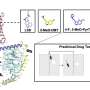
Although their application is new, their information-gathering methods are based on well-established text processing techniques. It's also simpler and faster than current strategies used in the same arena, said LePendu. Content is first grouped via "ontologies," which are information graphs organized by associative relationships instead of a rigid linear structure. For example, melanoma is a kind of skin cancer, and so is Kaposi's sarcoma; by knowing "skin cancer" encompasses both kinds of cancer, the search process picks up this medical knowledge. The system also de-identifies patient information in the process, so sensitive data, such as names and addresses, doesn't get revealed. With these methods, LePendu said, the technique allows them to process 11 million clinical notes in about seven hours on hardware no different from a laptop computer—a pace that other programs can't match.
The information is also current: It's generated from what is observed and recorded in the hospital or doctor's office. That's an advantage over the FDA's AERS reports, which rely on patients and health providers to make the additional effort to report adverse events.
The researchers developed the computerized method to sift through the contents of clinical notes in electronic medical records and used it to examine how often specific drugs and diseases were mentioned in roughly 10 million notes for about 1.8 million patients over 15 years. The goal was to organize these notes into a data-mining substrate they refer to as a patient-feature matrix. "Everyone is excited about the prospect of 'big data' mining on electronic health record data," Shah said. "We demonstrate it in practice."
Although clinical notes provide an excellent source of untapped information, this mining technique does have limitations. It requires a big database to extract accurate trends, and the volume of information the system sorts through makes it more useful for looking at common events, such as heart attacks, said Shah. He added that the FDA reporting system is probably still superior for looking at rare problems, which wouldn't occur in high enough volume at any single institution. Also, the system can't evaluate adverse drug reactions that are dose dependent.
But, the research team is working on refinements that will cull even more useful information from clinical notes, such as reports of reactions caused by drug combinations, the use of medications typically prescribed for one condition but found effective for treatment of a different health problem, or finding medical profiles of patients that fit a certain scenario.
"This method is exciting, and it raises the possibility that mining clinical notes can augment traditional pharmacovigilance monitoring," said Steve Goodman, MD, PhD, associate dean of clinical and translation research for the medical school who also co-chaired the 2012 Institute of Medicine committee that studied the safety of approved drugs. Goodman was not involved in the research. "It also takes advantage of electronic health records which are already there."
One downside is that most electronic health record systems are set up for patient care, not patient research, Goodman noted. In this study, the researchers mined a data system created for this kind of research, which isn't widely available. The researchers used the Stanford Translational Research Integrated Database Environment, known as STRIDE.