Engineering prosthetic voices
"Never heard me before." That's what William, a 9-year-old boy with a speech-language disorder, said the first time he used the prosthetic voice that Northeastern associate professor Rupal Patel made just for him.
In San Francisco on Thursday, Patel, who has joint appointments in the Bouvé College of Health Science and the College of Computer and Information Science, shared William's story with thousands of viewers at TEDWomen, a two and a half day conference organized by the nonprofit organization TED, devoted to "Ideas Worth Spreading." This year's TEDWomen focused on invention in all its forms. Patel's talk was livestreamed for a group of Northeastern students, faculty, and staff gathered at the Behrakis Center.
There are 2.5 million Americans like William who are unable to speak, Patel told the audience, and many of them use the same computerized voice to communicate. "That's millions of people worldwide who are using generic voices," she said.
So much of our personality is contained in our voice, Patel explained. Even though people with speech-language disorders retain the ability to control that element of speech that is critical for determining individuality, a grown man may still have the same prosthetic voice as a young girl.
Through a project launched simultaneously with her TEDWomen talk, Patel is trying to change that. She and her team at Northastern's Communication Analysis and Design Laboratory have developed a technology called VocaliD (voh-CAL'-ih-dee) that allows them to create prosthetic voices that sound like the people with the speech impairments they were designed for. As William's mother put it, "This is what William would have sounded like had he been able to speak," Patel told the audience.
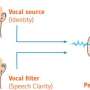
To create these voices, VocaliD extracts acoustic properties from a target talker's speech—whatever sounds they can still produce—and applies these features to a synthetic voice that was created from a surrogate voice donor who is similar in traits such as age, size, and gender. What is produced is a synthetic voice containing as much of the vocal identity of the target talker as possible yet the speech clarity of the surrogate talker.
By mixing the person's voice with that of a surrogate talker who has donated hours' worth of recorded sentences, the team can parse these sentences into "small snippets of speech" that can be reassembled into any other combination of words.
What happens next has been described by Patel's own daughter as "mixing colors to paint voices." William's vowel sound, for example, acts like a concentrated drop of red food dye. This is then mixed with the recorded speech snippets and infuses each of them with his unique vocal identity.
"So far we have a few surrogate talkers from around the U.S. who have donated their voices," she said. "We have been using and reusing them to build our first few personalized voices. But there's so much more work to be done."
With VocaliD.org, Patel has created a crowd-sourced portal for people around the world to donate their voices to the voiceless.
"We wouldn't dream of fitting a little girl with a prosthetic limb of a grown man," Patel said. "So why then the same prosthetic voice?" With VocaliD, that's longer necessary, she said.
More information: vocalid.org/