A facial expression is worth a thousand words
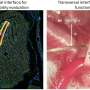
 is very difficult based on this photo alone. When showing the corresponding video sequence, however, recognition becomes easy, which underlines the importance of the temporal dimension for effective communication. Image: MPI für biologische Kybernetik / Christian Wallraven")
(PhysOrg.com) -- Moving pictures are more suitable to interpret the mood of a person than a static photograph.
Communication is a central aspect of everyday life, a fact that is reflected in the wide variety of ways that people exchange information, not only with words, but also using their face and body. Scientists from the Max Planck Institute for Biological Cybernetics in Tübingen, Germany, found out that we are able to recognize facial expressions in motion - for example in a movie - far better than in a static photograph. The video sequence needs to be at least as long as one tenth of a second to gain this dynamic advantage. (Journal of Vision, December 7th, 2009)
A facial expression can state a lot. A nod indicates understanding, a frown may say: "Please explain that again!" Scientists from the Max Planck Institute for Biological Cybernetics discovered that we are able to classify an expression much better when it moves naturally rather than when it is "frozen" in a photograph. In order to gain the advantage of dynamic information, we need to see the expression moving for at least 100 milliseconds. If the video sequence is shorter, our brain is less capable of interpreting the facial motion. Some expressions rely on changes in head orientation, for example, a nod or a shake of the head, others on the complex deformation of facial parts, such as wrinkling our nose to signalize disgust or a frown.
In order to examine to what extent we are able to recognize - based on facial expressions - the mood of a person with whom we are interacting, the scientists showed participants pictures of humans with various different expressions. Among them were simple, emotional expressions, such as "happy" and "sad", but also more complex ones such as agreement, confusion, or surprise, which are usually used to emphasize or modify statements in a conversation. In order to investigate whether these expressions are recognized more easily in motion or in static pictures, a short video sequence was shown to the participants. The video recordings began at a neutral expression, showed an emotion, and ended at the last frame before the face started to head back to a neutral expression. The frame used in the static conditions was the last, so-called ‘peak’ frame of each dynamic sequence. The participants were then asked to identify the expressions based on the shown sequence or single frame.
In further experiments, the video sequences were converted to a series of photographs that was shown to the participants.
Nevertheless, the expressions were still recognized more accurately in the video sequence. This showed that the dynamic advantage is not due to the presence of multiple images, but that some form of dynamic information is being used. In order to figure the degree to which facial expression recognition relies on natural movement, the frames were presented as a movie, but in a random order. Comparisons of the performance in this scrambled condition to the original video sequence shows that the recognition rates were still higher in the original than in the scrambled version.
The chronological direction is of importance as well. If the video sequences are temporally reversed, they are again identified less accurately. Finally, the more temporal information we receive, the better we are able to recognize expressions - at least up to 100 milliseconds. The results show that neither pictures, nor motion alone are of importance, but that we need a combination of the correct temporal sequence and the correct facial motion to reliably interpret facial expressions.
"Facial expressions, like gestures and body motion, are a dynamic phenomenon and need to be investigated with the help of video sequences in order to get a better understanding of the dynamic information that is being processed", says Dr. Christian Wallraven, co-author of the study. "Our results also have implications for the area of computer animation, since its goal is to create artificial avatars and facial animations that are able to communicate realistically and believably", says the physicist and perception scientist.
More information: Cunningham, D. W. & Wallraven, C. Dynamic information for the recognition of conversational expressions. Journal of Vision, 9 (13):7, 1-17; doi:10.1167/9.13.7