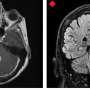
Learning strategies are associated with distinct neural signatures
The process of learning requires the sophisticated ability to constantly update our expectations of future rewards so we may make accurate predictions about those rewards in the face of a changing environment. Although exactly how the brain orchestrates this process remains unclear, a new study by researchers at the California Institute of Technology suggests that a combination of two distinct learning strategies guides our behavior.
A paper about the work will appear in the May 27 issue of the journal Neuron.
One accepted learning strategy, called model-free learning, relies on trial-and-error comparisons between the reward we expect in a given situation and the reward we actually get. The result of this comparison is the generation of a "reward prediction error," which corresponds to that difference. For example, a reward prediction error might correspond to the difference between the projected monetary return on a financial investment and our real earnings.
In the second mechanism, called model-based learning, the brain generates a cognitive map of the environment that describes the relationship between different situations. "Model-based learning is associated with the generation of a 'state prediction error,' which represents the brain's level of surprise in a new situation given its current estimate of the environment," says Jan Gläscher, a postdoctoral scholar at Caltech and the lead author of the study.
"Think about a situation in which you always take the same route when driving home after work, but on a particular day the usual way is blocked due to construction work," Gläscher says. "A model-free learning system would be helplessly lost; it is only concerned with taking actions that in the past were rewarding, so if those actions are no longer available it wouldn't be able to decide where to go next. But a model-based system would be able to query its cognitive map and figure out an efficient detour using an alternative route."
"Although the simpler model-free learning mechanism has been well studied and its basic learning mechanism—which is driven by reward prediction errors—is relatively well understood, the mechanisms underlying the more sophisticated model-based learning system, with its rich adaptability and flexibility, are less well understood" says John P. O'Doherty, professor of psychology at Caltech and the Thomas N. Mitchell Professor of Cognitive Neuroscience at Trinity College in Dublin, Ireland.
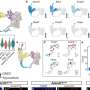
To further characterize the neurological underpinnings of these two learning systems, Gläscher, O'Doherty, and their colleagues designed a computer-based decision-making task that allowed them to measure when and where the brain computes both reward and state prediction error signals, and to determine if the two types of errors actually produce different neural signatures.
In the task, subjects had to make choices between a left and right movement that allowed them to shift between different "states"—denoted by graphical icons—in a virtual environment; the process is similar to that of navigating around in a simple video game. Each left-or-right choice made in this virtual environment led the subject to a new state. Their objective was to reach a particular goal state to obtain a monetary reward, "and their chances of ending up in that goal state strongly depended on the particular pattern of sequential choices they made," O'Doherty explains.
A model-based system can learn about the structure of the virtual environment and then use this information to compute the actions needed to get to the reward state, in a manner analogous to how a chess player might try to think through the sequential chess moves needed to win a match. A model-free system, on the other hand, would only learn to blindly choose those actions that gave reward in the past, without evaluating the consequences in the current situation.
Eighteen participants were scanned using functional magnetic resonance imaging as they learned the task. The brain scans showed the distinctive, previously characterized neural signature of reward prediction error—generated during model-free learning—in an area in the middle of the brain called the ventral striatum. During model-based learning, however, the neural signature of a state prediction error appeared in two different areas on the surface of the brain in the cerebral cortex: the intraparietal sulcus and the lateral prefrontal cortex.
These observations suggest that two unique types of error signals are computed in the human brain, occur in different brain regions, and may represent separate computational strategies for guiding behavior. "A model-free system operates very effectively in situations that are highly automated and repetitive—for example, if I regularly take the same route home from work," Gläscher says, "whereas a model-based system, although requiring much greater brain-processing power, is able to adapt flexibly to novel situations, such as needing to find a new route following a roadblock."
These two distinct learning mechanisms serve complementary roles in controlling human behavior, Gläscher says. "Because the processing power of our brains is limited, it doesn't make sense to deploy the more computationally intensive model-based system for controlling everything we do. Instead, it is better to rely on the model-free system for a lot of our everyday behavior and use the model-based system only for new or complex situations. An important area for further research will be to try to understand the factors governing how these systems interact together in order to control behavior, and to determine how this is implemented in the brain."
More information: O’Doherty et al.: “States versus Rewards: Dissociable Neural Prediction Error Signals Underlying Model-Based and Model-Free Reinforcement Learning.” Publishing in Neuron 66, 585-595, May 27, 2010. DOI 10.1016/j.neuron.2010.04.01