Sound sense: Brain 'listens' for distinctive features in sounds

For humans to achieve accurate speech recognition and communicate with one another, the auditory system must recognize distinct categories of sounds—such as words—from a continuous incoming stream of sounds. This task becomes complicated when considering the variability in sounds produced by individuals with different accents, pitches, or intonations.
In a recent Nature Communications paper, Shi Tong Liu, a bioengineering Ph.D. candidate at the University of Pittsburgh Swanson School of Engineering, details a computational model that explores how the auditory system tackles this complex task. The research is led by Srivatsun Sadagopan, assistant professor of neurobiology, whose lab studies the perception of complex sounds in realistic listening conditions.
"A 'word' may be pronounced in different ways by different voices, but you are still able to lump all of these utterances into a category (a specific word) with a distinct meaning," said Sadagopan. "In this study, we examined how the brain achieves this by using animal calls as a greatly simplified model system. Vocal animal species such as marmosets, macaques, and guinea pigs produce several types of calls which carry distinct behavioral 'meanings,' but they also face the problem that different animals produce these calls with a lot of variability."
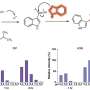
The published paper, "Optimal features for auditory categorization", focuses on vocalizations of the common marmoset. Xiaoqin Wang, professor of biomedical engineering at Johns Hopkins University, provided a large set of marmoset vocalizations that captured the wide range of variability in these sounds. The team then used information theory and a "greedy" search algorithm to find features of each vocalization type that consistently occurred despite all of the variability. Their strategy was to select a set of features that jointly maximized performance, but avoid features that were too similar to each other.
"We fed our algorithm a bank of marmoset calls and asked it to find the most informative and consistently recognizable features," explained Liu. "The final output was a set of 'most informative features' that are characteristic to a particular call type—much like the distinguishing features of a face (e.g. finding eyes or a nose in an image). By detecting the presence or absence of these most informative features in incoming sounds, the model can identify the vocalization type with very high accuracy."
After the features were shown to be effective in the theoretical model, the team returned to the animals to test if the brain was in fact looking for these informative features. They found interesting results when they compared data from their model to neural responses recorded from marmoset auditory cortex by Sadagopan when he was a graduate student in Xiaoqin Wang's lab.
"The neural evidence supports our model, which means it can be used as a solid foundation for future studies," said Liu. "Our model gives powerful and accurate predictions of what the brain is listening for in vocalizations. This research has applications in advancing speech recognition technology and auditory prostheses, and I plan to use this work to better understand how the brain can isolate relevant sounds in crowded spaces."
The team's work was supported by research grants from the National Institutes on Deafness and other Communication Disorders (NIDCD), the Pennsylvania Lions Hearing Research Foundation, and the Samuel and Emma Winters Foundation.
More information: Shi Tong Liu et al. Optimal features for auditory categorization, Nature Communications (2019). DOI: 10.1038/s41467-019-09115-y