This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
peer-reviewed publication
trusted source
proofread
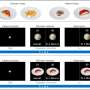
A machine learning framework that encodes images like a retina
; the image processed using non-learning computation (middle); and the image processed using the actor-model framework. Credit: EPFL CC BY SA")
EPFL researchers have developed a machine learning approach to compressing image data with greater accuracy than learning-free computation methods, with applications for retinal implants and other sensory prostheses.
A major challenge to developing better neural prostheses is sensory encoding: Transforming information captured from the environment by sensors into neural signals that can be interpreted by the nervous system. But because the number of electrodes in a prosthesis is limited, this environmental input must be reduced in some way, while still preserving the quality of the data that is transmitted to the brain.
Demetri Psaltis (Optics Lab) and Christophe Moser (Laboratory of Applied Photonics Devices) collaborated with Diego Ghezzi of the Hôpital ophtalmique Jules-Gonin—Fondation Asile des Aveugles (previously Medtronic Chair in Neuroengineering at EPFL) to apply machine learning to the problem of compressing image data with multiple dimensions, such as color, contrast, etc. In their case, the compression goal was downsampling, or reducing the number of pixels of an image to be transmitted via a retinal prosthesis.
"Downsampling for retinal implants is currently done by pixel averaging, which is essentially what graphics software does when you want to reduce a file size. But at the end of the day, this is a mathematical process; there is no learning involved," Ghezzi explains.
"We found that if we applied a learning-based approach, we got improved results in terms of optimized sensory encoding. But more surprising was that when we used an unconstrained neural network, it learned to mimic aspects of retinal processing on its own."
Specifically, the researchers' machine learning approach, called an actor-model framework, was especially good at finding a "sweet spot" for image contrast. Ghezzi uses Photoshop as an example. "If you move the contrast slider too far in one or the other direction, the image becomes harder to see. Our network evolved filters to reproduce some of the characteristics of retinal processing."
The results have recently been published in Nature Communications.
Validation both in-silico and ex-vivo
In the actor-model framework, two neural networks work in a complementary fashion. The model portion, or forward model, acts as a digital twin of the retina: It is first trained to receive a high-resolution image and output a binary neural code that is as similar as possible to the neural code generated by a biological retina. The actor network is then trained to downsample a high-resolution image that can elicit a neural code from the forward model that is as close as possible to that produced by the biological retina in response to the original image.
Using this framework, the researchers tested downsampled images on both the retina digital twin and on mouse cadaver retinas that had been removed (explanted) and placed in a culture medium. Both experiments revealed that the actor-model approach produced images eliciting a neuronal response more akin to the original image response than an image generated by a learning-free computation approach, such as pixel-averaging.
Despite the methodological and ethical challenges involved in using explanted mouse retinas, Ghezzi says that it was this ex-vivo validation of their model that makes their study a true innovation in the field.
"We cannot only trust the digital, or in-silico, model. This is why we did these experiments—to validate our approach."
Other sensory horizons
Because the team has past experience working on retinal prostheses, this was their first use of the actor-model framework for sensory encoding. But Ghezzi sees potential to expand the framework's applications within and beyond the realm of vision restoration. He adds that it will be important to determine how much of the model, which was validated using mice retinas, is applicable to humans.
"The obvious next step is to see how can we compress an image more broadly, beyond pixel reduction, so that the framework can play with multiple visual dimensions at the same time. Another possibility is to transpose this retinal model to outputs from other regions of the brain. It could even potentially be linked to other devices, like auditory or limb prostheses," Ghezzi says.
More information: Franklin Leong et al, An actor-model framework for visual sensory encoding, Nature Communications (2024). DOI: 10.1038/s41467-024-45105-5