Scientists Map Genetic Regulatory Elements for the Heart
(PhysOrg.com) -- Scientists have devised a new computational model that can be used to reveal genetic regulatory elements responsible for development of the human heart and maintenance of its function.
Although the teams focused on the heart, the computational method they developed is broadly applicable to other tissues, and was successfully used to identify regulatory elements for cells of the limbs and brain. Cataloging these regulatory sequences may improve understanding of diseases and lays the groundwork for improved medical treatments.
The research, conducted by scientists at the National Institutes of Health's National Center for Biotechnology Information (NCBI) and the University of Chicago, is published in the March 2010 issue of Genome Research and is available online.
All cells of the human body share the same set of 46 chromosomes with approximately 23,000 genes, but only specific subsets of those genes will be activated in individual organs and tissues. Cells in the heart and other tissues switch genes on and off in different cells and at different points in their life spans by using regulatory elements, segments of DNA that control gene expression and are scattered throughout the sequence of 3 billion letters of the human genome.
The computational model is a tool to detect those switches within vast stretches of DNA. It offers a glimpse into the genetic blueprint for development and maintenance of organs, and could give researchers new targets for the study of disease.
"These sequences are literally in the middle of nowhere, these tiny things in a sea of anonymous sequences," said Marcelo Nobrega, assistant professor of human genetics at the University of Chicago and one of the study authors. "The question was: How are you going to find those?"
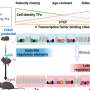
To conduct this difficult search, scientists at NCBI (a division of the National Library of Medicine at NIH) and the University of Chicago developed a machine learning approach to accurately detect signatures of heart regulatory elements. The machine learning approach involved the use of algorithms that enabled the computers to recognize complex patterns in the data and to improve the accuracy of recognition by automatically adapting the computational methods to the experimental data.
The research effort began with NCBI scientists analyzing segments of DNA already known to be heart regulatory elements and identifying combinations of short DNA segments, or motifs, that were common among those regulatory elements. "We then scanned the whole sequence of the human genome for other instances of similar motif combinations to find genetic signatures that would accurately predict heart regulatory activity," explained Leelavati Narlikar, an NCBI researcher who applied her machine learning expertise to the study and is lead author on the paper.
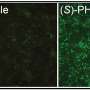
The resulting computer-predicted regulatory elements were then tested by the team at the University of Chicago, which attached the candidate elements to green fluorescent protein and injected them into zebrafish eggs. The researchers could confirm that the elements were active in heart cells by the green glow emanating from the zebrafish embryos.
The two research teams went through several cycles of training the computers to recognize the genetic code and testing the new predictions in zebrafish eggs to achieve the final set of predictions that would light up a high percentage of candidate regulatory elements in the heart.
"If you go randomly in the genome and pull out a sequence to test, the chance that you're going to hit a heart enhancer is probably going to be a fraction of a percent," Nobrega said. "Yet with our list of sequences, you have a 60 percent chance. It's tremendously better."
The ultimate tally of potential heart regulator sequences they found? Almost 42,000.
"Uncovering more than 40,000 novel stretches of DNA that control the activity of heart-related genes is an important step forward, as research to date has shown that many disease-associated changes in DNA lie in parts of the genome where biological function is not easily identified," said Alan M. Michelson, M.D., Ph.D., associate director for basic research at the National Heart, Lung, and Blood Institute (NHLBI), which co-funded the research. “This research gives us a whole new approach for understanding how individual genetic changes contribute to heart disease.”
"We can finally say that there is a well-defined genetic code hardwired in our genomes that can be used to specifically identify heart regulatory elements in the vast sequence that makes up the human genome," said Ivan Ovcharenko, who led the NCBI team and is a coauthor on the paper. "With the advance of computational methods, we can use computers to break this code, learn its encryption, and understand the signals heart cells receive to regulate genes."
"The novel classifier developed by Drs. Nobrega and Ovcharenko and their colleagues will provide a significant new tool for scientists trying to unravel the intricate regulatory code controlling heart formation," said Brian Black, professor and associate director of the Cardiovascular Research Institute at the University of California, San Francisco.
The University of Chicago research was co-funded by NHLBI and the National Human Genome Research Institute at NIH.
The University of Chicago Medical Center, established in 1927, is one of the nation's leading academic medical institutions. Care is provided by more than 700 attending physicians — most of whom are full-time University faculty members — 620 residents and fellows, more than 1,000 nurses and 9,000 employees. The Medical Center is consistently recognized as a leading provider of sophisticated medical care.