July 8, 2024 dialog
This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
peer-reviewed publication
trusted source
written by researcher(s)
proofread
Researchers built dozens of COVID-19 forecasting models—did they actually help?
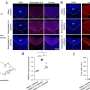
 Visual overlay of real case counts and predicted case counts across all waves examined. Actual case counts are shown in red, predicted counts are shown in gray with each trace representing a different CDC COVID-19 forecasting model on the sqrt plot. (B) MAPE values of US-CDC case prediction models on the complete timeline, i.e., Wave-I to IV. The y-axis is sorted descending from lowest error to highest. The color scheme represents the model category. (C) Bar graph showing the non-parametric Kruskall-Wallis test results. A Mann-Whitney test was further performed for groups with significant differences. Category-wise error was achieved by the models both overall and wave-wise from wave-1 to wave-4. Note that Hybrid models have a high MAPE, i.e., overall: 261.16%, Wave 1: 25.36%, Wave 4: 99.3%, Wave 3: 1421.325%, Wave 4: 54.74%). Credit: Aviral Chharia")
Accurate modeling is crucial during pandemics for several reasons. Political bodies must make policy decisions, which can take weeks to become law and even longer to implement. Similarly, public health organizations such as hospitals, schools, daycares, and health centers require advanced planning for severe surges and distribution of critical resources such as staff, beds, ventilators, and oxygen supply.
Accurate forecasting models can aid in making informed decisions regarding necessary precautions for specific locations and times, identifying regions to avoid traveling to, and assessing risks associated with activities like public gatherings.
During the COVID-19 pandemic, dozens of forecasting models were proposed. Even though their accuracy over time and by model type remains unclear, these were used in framing policy to varying degrees.
The main questions
Our recent study, published in Frontiers in Public Health, aimed to answer several important questions pertinent to pandemic modeling.
First, can we establish a standardized metric to evaluate pandemic forecasting models? Second, what were the top-performing models during the four COVID-19 waves in the US, and how did they perform on the complete timeline? Third, are there specific categories or types of models that significantly outperform others? Fourth, how do model predictions fare with increased forecast horizons? Finally, how do these models compare against two simple baselines?
Not fit for policy framing
The main results of the study show that more than two-thirds of models fail to outperform a simple static case baseline, and one-third fail to outperform a simple linear trend forecast.
To analyze models, we first categorized them into epidemiological, machine learning, ensemble, hybrid and other approaches. Next, we compared estimates made by the models to the government-reported case numbers and with each other, as well as against two baselines wherein case counts remain static or follow a simple linear trend.
This comparison was conducted wave-wise and on the entire pandemic timeline, revealing that no single modeling approach consistently outperformed or was superior to others, and modeling errors increased over time.

What went wrong and how to fix it?
What went wrong and how do we bridge that gap? Enhanced data collection is crucial as modeling accuracy hinges on data availability, particularly during early outbreaks. Currently, models rely on case data from diverse reporting systems that vary by county and suffer from regional and temporal delays. Some counties, for example, may gather data over many days and make it public all at once, giving the impression of a sudden burst of cases. The lack of data can limit modeling accuracy in counties with less robust testing programs.
Also, these methods are not uniform between data collection groups, resulting in unpredictable errors. Standardizing data formats could simplify data collection, reducing unpredictable errors.
Underlying biases in data, such as under-reporting, can produce predictable errors in model quality, requiring models to be adjusted to predict future erroneous reporting rather than actual case numbers. For example, the availability of rapid home test kits has led many individuals not to report test results to government databases. Serology data and excess mortality have identified such under-reporting.
Looking ahead
Even though enormous progress has been made, models still need to be better on various fronts, making more realistic assumptions on the effect the spread of multiple variants has on case numbers, immunity boosted by vaccination programs, the impact lockdowns have had, the presence of numerous virus variants, the rise of vaccination, the number of doses given to a patient, varying vaccination rates in different counties and varying lockdown mandates.
All these factors affect case numbers, which complicates the forecasting task. Even in the case of ensemble models, the study showed that these added individual model errors and thus did not show any significant difference in performance.
The model forecasting error in the U.S. CDC database increased each week from the time of prediction. In other words, the prediction accuracy declined the further out they were made. At one week from the time of the forecast, the prediction errors of most models clustered just below 25% but increased to about 50% in four-week forecasting.
This suggests that current models may not provide sufficient lead time for health entities and governments to implement effective policies.

Accurate predictive modeling remains essential in combating future pandemics. However, the study raises concerns when a policy is formulated directly based on these models. Models with high errors in predictions might lead to the heterogeneous distribution of resources such as masks and ventilators, which may lead to a risk of unnecessary mortality.
Further, hosting these models on official public platforms of health organizations (including the U.S. CDC) risks giving them an official imprimatur. The study suggests that developing more sophisticated pandemic forecasting models should be a priority.
This story is part of Science X Dialog, where researchers can report findings from their published research articles. Visit this page for information about Science X Dialog and how to participate.
More information: Aviral Chharia et al, Accuracy of US CDC COVID-19 forecasting models, Frontiers in Public Health (2024). DOI: 10.3389/fpubh.2024.1359368
Aviral Chharia is a graduate student at Carnegie Mellon University. He has been awarded the ATK-Nick G. Vlahakis Graduate Fellowship at CMU, the Students’ Undergraduate Research Graduate Excellence (SURGE) fellowship at IIT Kanpur, India, and the MITACS Globalink Research Fellowship at the University of British Columbia. Additionally, he was a two-time recipient of the Dean’s List Scholarship during his undergraduate studies. His research interests include Human Sensing, Computer Vision, Deep Learning, and Biomedical Informatics.
Christin Glorioso, MD PhD, is a computational biologist, physician, and serial entrepreneur. She is the co-founder and CEO of the Academics for the Future of Science, a non-profit science advocacy and research organization and the parent company of Global Health Research Collective. She received her Ph.D. in Neuroscience and MD from the Carnegie Mellon University-University of Pittsburgh School of Medicine and was a postdoctoral scholar at MIT.