Study of jazz players shows common brain circuitry processes music and language
The brains of jazz musicians engrossed in spontaneous, improvisational musical conversation showed robust activation of brain areas traditionally associated with spoken language and syntax, which are used to interpret the structure of phrases and sentences. But this musical conversation shut down brain areas linked to semantics—those that process the meaning of spoken language, according to results of a study by Johns Hopkins researchers.
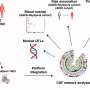
The study used functional magnetic resonance imaging (fMRI) to track the brain activity of jazz musicians in the act of "trading fours," a process in which musicians participate in spontaneous back and forth instrumental exchanges, usually four bars in duration. The musicians introduce new melodies in response to each other's musical ideas, elaborating and modifying them over the course of a performance.
The results of the study suggest that the brain regions that process syntax aren't limited to spoken language, according to Charles Limb, M.D., an associate professor in the Department of Otolaryngology-Head and Neck Surgery at the Johns Hopkins University School of Medicine. Rather, he says, the brain uses the syntactic areas to process communication in general, whether through language or through music.
Limb, who is himself a musician and holds a faculty appointment at the Peabody Conservatory, says the work sheds important new light on the complex relationship between music and language.
"Until now, studies of how the brain processes auditory communication between two individuals have been done only in the context of spoken language," says Limb, the senior author of a report on the work that appears online Feb. 19 in the journal PLOS ONE. "But looking at jazz lets us investigate the neurological basis of interactive, musical communication as it occurs outside of spoken language.
"We've shown in this study that there is a fundamental difference between how meaning is processed by the brain for music and language. Specifically, it's syntactic and not semantic processing that is key to this type of musical communication. Meanwhile, conventional notions of semantics may not apply to musical processing by the brain."
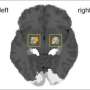
To study the response of the brain to improvisational musical conversation between musicians, the Johns Hopkins researchers recruited 11 men aged 25 to 56 who were highly proficient in jazz piano performance. During each 10-minute session of trading fours, one musician lay on his back inside the MRI machine with a plastic piano keyboard resting on his lap while his legs were elevated with a cushion. A pair of mirrors was placed so the musician could look directly up while in the MRI machine and see the placement of his fingers on the keyboard. The keyboard was specially constructed so it did not have metal parts that would be attracted to the large magnet in the fMRI.
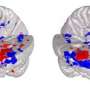
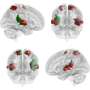
The improvisation between the musicians activated areas of the brain linked to syntactic processing for language, called the inferior frontal gyrus and posterior superior temporal gyrus. In contrast, the musical exchange deactivated brain structures involved in semantic processing, called the angular gyrus and supramarginal gyrus.
"When two jazz musicians seem lost in thought while trading fours, they aren't simply waiting for their turn to play," Limb says. "Instead, they are using the syntactic areas of their brain to process what they are hearing so they can respond by playing a new series of notes that hasn't previously been composed or practiced."