Refinement of an algorithm for determining genetic ancestry could help identify genetic factors in disease
")
A statistical algorithm for determining genetic ancestry has been improved by A*STAR researchers, an advance that could increase the sensitivity and accuracy of studies that aim to link genetics with disease.
Developments in genetic sequencing technology have accelerated the collection of genetic information, providing new opportunities to identify genetic mechanisms of disease. However, study designs must account for the genetic ancestry of included individuals.
"Genetic association studies seek to identify genes that are linked with genetic diseases or traits," explains Chaolong Wang from the A*STAR Genome Institute of Singapore. "Such efforts can be complicated by the underlying genetic ancestry in study samples because different populations have distinct genetic backgrounds."
These genetic backgrounds, as well as environmental factors, can influence disease susceptibility and accurate ancestry information among study populations helps avoid links between genes and disease being missed or misidentified. "Knowledge of individual ancestry can help researchers better pinpoint genes that are truly associated with disease," Wang says.
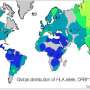
Wang and colleagues previously developed an algorithm designed to determine the ancestry of an individual from a small percentage of their genetic sequence. The algorithm, called 'Locating Ancestry from Sequence Reads', or 'LASER' 1.0, could establish continental ancestry, such as distinguishing between European and Asian ancestry. However, it was not refined enough to pinpoint fine-scale ancestry, such as the country of origin within Europe, when little genetic information was available from each person. The team have now developed LASER 2.0, which compares genetic information from individuals in an extensive ancestry reference dataset.
The team used LASER 2.0 to analyze genetic data that was previously studied with LASER 1.0. The new algorithm could estimate fine-scale European ancestry much more accurately than the original. The researchers also showed that when the available genetic data are insufficient, LASER 2.0 can use reference data to 'guess' some of the missing data, effectively increasing the amount of information for analysis.
LASER 2.0 could also accurately determine ancestry using genetic data collected from different sources or generated with different techniques. This ability is the most significant improvement over LASER 1.0 because it enables more data to be collated and analyzed, thereby increasing sensitivity to genetic associations with disease.
"LASER 2.0 can help reduce spurious associations being made by modeling the differences in ancestry within the study sample," explains Wang. "The facilitation of integrative analysis of genetic data from different sources should accelerate discovery in large-scale disease association studies. Our method could also provide insight into relationships between ancient and modern human DNA."
More information: "Improved ancestry estimation for both genotyping and sequencing data using projection procrustes analysis and genotype imputation." American Journal of Human Genetics 4, 926–937 (2015). dx.doi.org/10.1016/j.ajhg.2015.04.018