A 'big data' approach to developing cancer drugs

Scientists are starting to accumulate huge datasets on which genes mutate during cancer, allowing for a more systematic approach to "precision medicine." In a study publishing July 7 in Cell, researchers compared genetic mutations in patient tumors to those in cancer cell lines and then tested the cell lines' responses to therapeutic compounds. By analyzing where these datasets overlap, researchers can begin to predict on a large scale which drugs will best fight various cancers.
"The process that we've done, by nature, is a discovery process," says Mathew Garnett, a cancer biologist at the Wellcome Trust Sanger Institute. "It's the beginning of generating exciting new ideas about how we might target specific patient populations with specific drugs. This type of study wasn't possible a few years ago because we hadn't sequenced enough patient tumors."
When developing new anti-cancer drugs, researchers often rely first on cancer cell lines in the lab. "You can't screen hundreds of drugs across a single patient. It's not possible," says Ultan McDermott, a cancer clinician and researcher also at the Sanger Institute. "But you can do that with cell lines—you can expose them to many different drugs and ask questions about which is more or less sensitive."
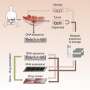
How closely these cell lines match what actually happens in a human tumor has been unclear, however, and previous efforts to model drug response using cancer cell lines were done on a relatively small scale. To investigate a larger piece of the landscape, Garnett, McDermott, and their colleagues analyzed data from two public datasets, The Cancer Genome Atlas and the International Cancer Genome Consortium, and other studies, gathering genetic information for more than 11,000 tumor samples.
The team then compared these tumor samples to about 1,000 cancer cell lines used in labs, looking for lines that had the same types of mutations as the patient samples—and therefore might more closely mimic patient responses. "Many of the cell lines do capture the molecular features that are important to human beings in cancer," says McDermott.
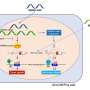
Once they mapped the tumor mutations onto the cell lines, the researchers looked for the genetic mutations that could best predict the cancer cells' response to 265 different anti-cancer compounds at various stages of development. The drugs covered a range of mechanisms, including chemotherapeutics, small-molecule inhibitors, epigenetic modulators, and cell death regulators.
Many of the mutations that occurred both in tumor samples and cell lines did signal whether the cancer cells would be sensitive or resistant to different compounds, largely depending on the type of tissue the cancer originated in. "If you can identify the clinically relevant features in cell lines and correlate those with drug response, you're one step closer to identifying a drug interaction that could be important for a patient," says McDermott.
"We've taken a leap forward in doing this type of study in a very comprehensive and systematic way, as opposed to what often is done, where someone might do it with a single drug or in a single cell line," explains Garnett. "It's by no means the end of the journey—but it's a huge milestone."
Going forward, the researchers are creating a web portal to share their data, which will allow cancer researchers to see which cell lines most closely mirror the patient condition they aim to emulate and how those cell lines respond to different drugs. Garnett and McDermott's teams are also starting their own follow-up projects to investigate associations between certain cell mutations and drug effects, with the hope of more clearly pinpointing which cancer patients will most benefit from a given compound.
More information: Cell, Iorio et al.: "A landscape of pharmacogenomic interactions in cancer" www.cell.com/cell/fulltext/S0092-8674(16)30746-2 , DOI: 10.1016/j.cell.2016.06.017