New computational strategy designed for more personalized cancer treatment

Mathematicians and cancer scientists have found a way to simplify complex biomolecular data about tumors, in principle making it easier to prescribe the appropriate treatment for a specific patient.
The new computational strategy transforms highly complex information into a simplified format that emphasizes patient-to-patient variation in the molecular signatures of cancer cells, the researchers say.
The digital approach from scientists at the Johns Hopkins University was detailed recently in the journal Proceedings of the National Academy of Sciences.
"The main point of this paper was to introduce this methodology," said Donald Geman, a professor in the Department of Applied Mathematics and Statistics who was senior author of the PNAS article. "And it also reports on some preliminary experiments using the method to distinguish between closely related cancer phenotypes."
A key challenge for doctors is that each primary form of cancer, such as breast or prostate, may have multiple subtypes, each of which responds differently to a given treatment.
"One of the things that people in this field have noticed over the past 10 years—and, in fact, it has been startling—is how much heterogeneity there is even between two patients with the same subtype of cancer," Geman said. "By that, I mean that in two patients who were both diagnosed with melanoma, the skin lesions may look quite similar to the naked eye but the cancerous cells may be very different at the molecular level. They may have different forms of dysregulation, including different genetic variants and different gene expression profiles."
Knowing as much as possible about the genetic makeup and impaired biological pathways of a particular patient could help physicians make more informed decisions about the prognosis and treatment, adjusting them to the particular molecular profile.
"They want to know if they are looking at a profile of a woman who likely will or will not respond to a particular drug," Geman said. "Or does the data indicate the patient will likely relapse within the next five years? Or does a man have a particularly aggressive type of prostate cancer? Or is it necessary to surgically remove the lymph nodes to determine the presence or absence of metastases in a patient with some form of head and neck cancer?"
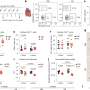
To help provide answers, Geman and his team envisioned something similar to the bloodwork summaries commonly produced when a patient visits a doctor for an annual physical exam. These generally report whether blood sugar, cholesterol and other results are within or are outside of healthy levels. Taking a cue from these tests, Geman's team found a way to greatly simplify the data on tens of thousands of molecular states by converting these data to binary labels, indicating whether a measurement falls within or beyond healthy levels.
Geman, who previously devoted many years to improving computer vision technology, is encouraged by the cancer-related project and hopes it will serve as a model for other fruitful collaborations involving advanced math and medicine.
"The goal," he said, "is taking classification problems of genuine clinical interest and producing an algorithm that is accurate, interpretable and makes sense biologically."
More information: Wikum Dinalankara et al, Digitizing omics profiles by divergence from a baseline, Proceedings of the National Academy of Sciences (2018). DOI: 10.1073/pnas.1721628115