Machine learning models identify kids at risk of lead poisoning

Machine learning can help public health officials identify children most at risk of lead poisoning, enabling them to concentrate their limited resources on preventing poisonings rather than remediating homes only after a child suffers elevated blood lead levels, a new study shows.
Rayid Ghani, Distinguished Career Professor in Carnegie Mellon University's Machine Learning Department and Heinz College of Information Systems and Public Policy, said the Chicago Department of Public Health (CDPH) has implemented an intervention program based on the new machine learning model and Chicago hospitals are in the midst of doing the same. Other cities also are considering replicating the program to address lead poisoning, which remains a significant environmental health issue in the United States.
In a study published today in the journal JAMA Network Open, Ghani and colleagues at the University of Chicago and CDPH report that their machine learning model is about twice as accurate in identifying children at high risk than previous, simpler models, and equitably identifies children regardless of their race or ethnicity.
Elevated blood lead levels can cause irreversible neurological damage in children, including developmental delays and irritability. Lead-based paint in older housing is the typical source of lead poisoning. Yet the standard public health practice has been to wait until children are identified with elevated lead levels and then fix their living conditions.
"Remediation can help other children who will live there, but it doesn't help the child who has already been injured," said Ghani, who was a leader of the study while on the faculty of the University of Chicago. "Prevention is the only way to deal with this problem. The question becomes: Can we be proactive in allocating limited inspection and remediation resources?"
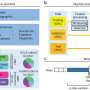
Early attempts to devise predictive computer models based on factors such as housing, economic status, race and geography met with only limited success, Ghani said. By contrast, the machine learning model his team devised is more complicated and takes into account more factors, including 2.5 million surveillance blood tests, 70,000 public health lead investigations, 2 million building permits and violations, as well as age, size and condition of housing, and sociodemographic data from the U.S. Census.
This more sophisticated approach correctly identified the children at highest risk of lead poisoning 15.5% of the time—about twice the rate of previous predictive models. That's a significant improvement, Ghani said. Of course, most health departments currently aren't identifying any of these children proactively, he added.
The study also showed that the machine learning model identified these high-risk children equitably. That's a problem with the current system, where Black and Hispanic children are less likely to be tested for blood lead levels than are white children, Ghani said.
In addition to Ghani, the research team included Eric Potash and Joe Walsh of the University of Chicago Harris School of Public Policy; Emile Jorgensen, Nik Prachand and Raed Manour of CDPH; and Corland Lohff of the Southern Nevada Health District. The Robert Wood Johnson Foundation supported this research.
More information: JAMA Network Open (2020). DOI: 10.1001/jamanetworkopen.2020.12734