Scientists develop gene test to accurately classify brain tumors
Scientists at The Wistar Institute have developed a mathematical method for classifying forms of glioblastoma, an aggressive and deadly type of brain cancer, through variations in the way these tumor cells "read" genes. Their system was capable of predicting the subclasses of glioblastoma tumors with 92 percent accuracy. With further testing, this system could enable physicians to accurately predict which forms of therapy would benefit their patients the most.
Their research was performed in collaboration with Donald M. O'Rourke, M.D., a neurosurgeon at the University of Pennsylvania Brain Tumor Center, who provided the glioblastoma samples necessary to validate the Wistar computer model. Their findings were published online in the journal Nucleic Acids Research.
"It has become increasingly obvious that understanding the molecular makeup of each patient tumor is the key to personalizing cancer treatments for individual patients," said Ramana Davuluri, Ph.D., Wistar's Tobin Kestenbaum Family Professor and associate director of Wistar's Center for Systems and Computational Biology. "We have developed a computational model that will allow us to predict a patient's exact variety of glioblastoma based on the transcript variants a given tumor produces."
"A gene can produce multiple variants, in the form of transcript variants and protein-isoforms. We found that when you use the gene expression information at variant/isoform-level, the statistical analyses recaptured the four known molecular subgroups but with a significant survival difference among the refined subgroups." said Davuluri. "Using patient data, we found that certain subgroups when combined with patient age, for example, could predict better outcomes using a given course of therapy."
"As more targeted therapies come into use, this is exactly the sort of information clinicians will need to provide the best hope of survival for their patients," Davuluri said. "In time, we think this could form the basis of a clinical test that will help oncologists decide a patient's course of treatment."
Glioblastoma multiforme is the most lethal of the malignant adult brain tumors, and accounts for over 50 percent of all cases of brain cancer. Even with aggressive combination therapies, the prognosis remains bleak, with median patient survival of 15 months after diagnosis. The disease is also molecularly heterogeneous, that is, composed of subtypes that are not genetically alike or produce the same array of proteins. Genetic data from the Cancer Genome Atlas (TCGA) consortium has led to the identification of four subtypes of glioblastoma, but Davuluri and his researchers sought to find a way to quickly identify which patient was which subtype.
In previous studies, Davuluri and his Wistar colleagues have established how changes in the way a cell reads its own DNA can create multiple variations of a single protein. These variant proteins are called isoforms, and they are produced as cells alter how they transcribe a given gene into RNA. Slight changes in how the cellular machine reads a gene can result in protein isoforms with subtle differences in enzymatic activity or longevity.
For example, their earlier research determined how human brains produce different isoforms of specific proteins throughout their lives. Developing fetal brains produce different isoforms of certain genes than adult brains. They also found that changes that trigger the production of the wrong isoform at the wrong time could lead to cancer.
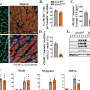
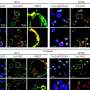
In the Nucleic Acids Research study, the researchers combined assays of these protein isoforms with a computer model they call PIGExClass, or the Platform-independent Isoform-level Gene-EXpression based Classification-system. To categorize glioblastomas with PIGExClass, Davuluri and his colleagues first began with Cancer Genome Atlas data to develop a set of 121 isoform variants whose combination of differences could denote a specific subtype of the brain cancer. PIGExClass is, essentially, a software that ranks gene isoform data into sets based on a set of pre-determined values. The researchers found that, by using this classification system, they could predict the subtype of glioblastoma in the database with 92 percent accuracy.
"When we knew what combination of isoforms could create a specific signature for each type of glioblastoma, we could then create a simple laboratory assay that would look for these differences in patient samples," Davuluri said. "In this case the test would measure variations in the RNA abundance associated with these 121 isoforms that make up the signature."
With this new assay in hand, the researchers validated their research using 206 independent samples from the University of Pennsylvania Brain Tumor Tissue Bank. According to Davuluri, when you accounted for differences in the makeup of the pools of patients between TCGA and Penn, the accuracy of the assay remained the same.