Using artificial intelligence to improve reporting of medication errors
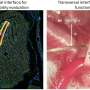
 the SOM nodes are arbitrarily positioned in the data space. The node (highlighted in yellow) which is nearest to the training datum is selected. It is moved towards the training datum, as (to a lesser extent) are its neighbors on the grid. After many iterations, the grid tends to approximate the data distribution (right). Credit: DOI: 10.1016/j.array.2020.100049")
A novel machine-learning method has teased out factors that are responsible for nurses reporting, or failing to report, non-critical errors in dispensing medication
Medical errors are more common than many people think, and the most frequent type comes from dispensing medication. However, non-critical errors are rarely reported. An interdisciplinary group of scientists led by Renjie Hu from the University of Iowa, Iowa City, U.S. has developed a computational methodology for predicting factors that make nurses more likely to report errors. This work is published with open access in the Elsevier journal Array.
More people in the US die from medical errors every year than from breast cancer, AIDS and car accidents combined. However, these incidents only form the tip of the iceberg; all types of medical error, including medication errors, are grossly under-reported unless they cause severe harm to the patients concerned. The actual report rate may even be as low as five percent.
In a typical hospital, nurses are involved in administering around 40 percent of medications; even if they don't give the drugs themselves, they are often able to observe them being given. Despite the responsibility placed on them, they state many reasons for not reporting errors, particularly when no serious harm has ensued. These include fear of blame and retaliation from their managers and their peers.
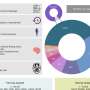
There are many factors that might influence whether, following any given incident, the nurse concerned will report an error. These include factors to do with nurses' relationships with their managers, how much they feel that they belong to the institution, and questions of trust as well as basic demographic characteristics.
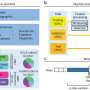
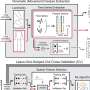
The computational method developed by Hu and his colleagues uses two distinct machine-learning approaches to search for, and then visualize, patterns in the data that suggest which factors are most important in determining nurses' behavior in different circumstances. "This is a novel, powerful method that is able to combine non-linear analysis and visualization to reveal non-linear factors (such as human behavior) in the data and to guide senior hospital staff to improve their management," says Hu.
The researchers considered three types of medication error of increasing severity: where a mistake was caught and corrected before it was made; where the mistake was made but there was no potential harm to the patient; and where the patient might have been harmed but was not. They collected relevant data about nurses, their managers and institutions and their stated likelihood of reporting the three types of error from surveys, and used this in parallel neural networks to identify those variables that were most associated with high and low likelihood of reporting mistakes.
The most predictive variables were visualized on colored grids using another machine-learning technique: Self-Organizing Maps. "This visual analysis gave us a comprehensive analysis of selected variables," adds Hu. It showed clear differences between the least severe errors, where nurses' judgements were affected most by the attitudes of their peers, and more serious ones, where the managers' attitudes were more important.
More information: Renjie Hu et al, Using machine learning to identify top predictors for nurses' willingness to report medication errors, Array (2020). DOI: 10.1016/j.array.2020.100049