Kidney disease mutations found in a genomic blind spot
")
(Medical Xpress)—Advances in DNA sequencing technology during the past decade have given scientists powerful tools to peer into the genomes of humans and other species. Despite the efficiency and sophistication of these technologies – known as massively parallel, or next-generation, sequencers – some of the genome's secrets still remain hidden.
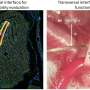
One example is the rare kidney disorder known as MCKD1, a condition that ultimately requires dialysis or kidney transplantation for patients. For decades, scientists have known the genetic "neighborhood" of the mutation causing MCKD1, a 2-million-base region on chromosome 1, but they have so far been unsuccessful in narrowing in on the mutation itself.
The genetic misspelling underlying MCKD1 has now been revealed through work by a team of Broad Institute scientists led by institute director Eric Lander and senior associate member Mark Daly, also founding chief of the Analytic and Translational Genetics Unit at Massachusetts General Hospital. The work appears in the February 10 online edition of Nature Genetics and was supported primarily through the Slim Initiative in Genomic Medicine, an international collaboration between the Broad and the National Institute of Genomic Medicine in Mexico City, known by its Spanish acronym INMEGEN.
In this study, the researchers dusted off more traditional genetic sequencing and analysis methods to discover a single disease-causing mutation lying in a "blind spot" of modern sequencing techniques. The work opens the door for potential new therapeutic approaches for this disease, provides insight that may one day help physicians treating patients with MCKD1, and offers a model for studying similar unsolved mysteries of human genetics.
Daly, Lander, and first author and Broad researcher Andrew Kirby have long been interested in how the dysfunction of genes leads to disease. "This is what has driven our careers for decades now," said Daly. The mutation underlying MCKD1 had been an outstanding challenge in the field, and although scientists have known the rough location of the causal mutation on chromosome 1 for 15-20 years, no one had managed to find it yet. "It was a particularly interesting challenge," Daly added.
The researchers initially set out hoping to find a simple, rare change in protein-coding DNA that might be the disease cause. After using massively parallel sequencing to analyze the DNA of patients with MCKD1 from six families, they came up empty-handed. A search for variants in the non-coding portions of this region of chromosome 1 also failed to reveal the mutation. After entertaining a few other plausible scenarios, the researchers wondered if the mutations might be hiding in a part of the genome that sequencers routinely miss, a technical blind spot.
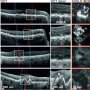
In many places in the genome, short segments of DNA repeat, and these so-called "variable number tandem repeats," or VNTRs, are notoriously difficult to read with next-generation sequencers. The researchers scanned the neighborhood on chromosome 1 for VNTRs that might be at play and highlighted five genes harboring repetitive segments. Four of the five were quickly excluded as candidates, leaving a VNTR in the MUC1 gene as a suspect.
Through careful and painstaking work using decades-old genome sequencing and analysis methods, the team discovered that the MUC1 gene had been annotated incorrectly as non-coding by most resources, although it has been known that this region codes for protein since the 1980s. "The region is so challenging to sequence, even the Human Genome Project had not accurately reported the full sequence of this gene," said Daly.
The MUC1 gene harbors a relatively "unreadable" 60-letter repeat unit that is duplicated anywhere from 30 to 80 times in the gene. "The sequence content of this region makes it very problematic for every stage of a sequencing effort, from generating accurate sequence data to processing and assembling those data," explained Kirby. After carefully studying the size of the VNTR in the MUC1 gene in the affected families, the researchers ruled out repeat length as the cause and decided to look for single-letter, or point, mutations within that sequence.
Through meticulous work by the Broad's genomic assembly team, the researchers discovered that the MUC1 gene in patients with MCKD1 harbors an insertion of a single cytosine residue in one copy of the repeat unit, producing an abnormal form of the gene's protein and leading to MCKD1. In each family studied, the C was inserted into a different copy of the repeat unit, so although the nature of the mutation was the same across families, each version produced a slightly different malfunctioning protein.
With plans to expand their investigation, members of the team developed a clever assay that can quickly and reliably identify the C-insertion in MUC1, enabling follow-up studies in a larger population. The researchers and colleagues nearby and around the world are studying the MUC1 alteration further to understand its functional consequences. "Finding the gene was the first step," said Daly. "Now we want to explore and understand the function of these mutations, and see if that explanation leads us to identifying potential therapeutic leverage points."
The assay and knowledge of the mutation itself could have clinical relevance soon. While MCKD1 now gets diagnosed in the third or later decades of life, individuals might learn much earlier if they are carriers for the disease, potentially informing treatment decisions or helping ensure that kidney donors are not latent carriers of these mutations.
Beyond the clinical implications of the work, this study provides a model for similar puzzles of human genetics. "There are many rare and severe genetic disorders that have been mapped to regions of the genome, but haven't yet had the causal mutation identified," said Daly, adding that the insights from this work could be applied to those problems as well.
Another lesson from the work lies in these blind spots of massively parallel sequencers. "It's prompted us to identify other genes that for various reasons we're not technically assessing [with modern sequencers]. Understanding those missing segments is certainly important," said Daly.
The work is a good reminder for researchers to hold onto techniques that may have been replaced by more sophisticated, high-throughput techniques. "Many of the steps in this work relied on methods we used to do quite routinely 10 to 20 years ago," said Daly.
First author Kirby added, "It's a lesson that needs to be relearned with every new technology. They all have their own blind spots."
More information: Kirby, et al. Mutations causing medullary cystic kidney disease type 1 lie in a large VNTR in MUC1 missed by massively parallel sequencing. Nature Genetics. February 10, 2013. DOI:10.1038/ng.2543