Redefining colorectal cancer subtypes

There is a long-standing belief that colorectal cancer (CRC), which causes some 50,000 deaths in the United States each year, can be categorized into distinct molecular subtypes. In a paper published recently in the journal Genome Biology, CUNY SPH Associate Professor Levi Waldron and colleagues challenged this basic assumption and proposed an approach to scoring tumors that can help to better differentiate patients who may differ in their exposures, outcomes, and optimal treatments.
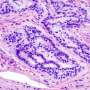
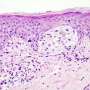
In the study, the authors re-processed and standardized individual patient gene expression data for more than 3,700 patients from 18 published studies, creating the largest such standardized, curated database of the CRC "transcriptome" to date. The authors first attempted to validate widely accepted subtypes of CRC and found no evidence to support these or other discrete subtypes of the CRC "transcriptome," or combined pattern of expression of all genes.
The authors then proposed a novel method to use such a database to identify either discrete subtypes or continuous scores to provide simplifying measures of the transcriptome. They used it to identify two validated scores to better characterize a continuity of CRC transcriptomes. These subtype scores are consistent with previously established subtypes, but better represent the individual variability of CRC than do discrete subtypes. The scores are better predictors of tumor location, stage, grade, and times of disease-free survival, and can be understood as representing biological activity including inflammation and immune activity.
"This work re-examines methods that have been widely used to identify cancer subtypes across many areas of cancer research and shows that those methods may identify tumor subsets that don't exist on further validation," Waldron says. "But the most exciting part of this work is that it provides a new way to leverage publicly available databases to understand major patterns of transcriptome variation in a way that is robust even to widespread heterogeneity of the patient cohorts and to technical artifacts. The robustness of our proposed scoring system is clear and hard to dispute. I'm looking forward to applying this approach now for other cancer types and in the even larger databases now available, to better understand how different peoples' tumors are similar and how they are different."
More information: Siyuan Ma et al. Continuity of transcriptomes among colorectal cancer subtypes based on meta-analysis, Genome Biology (2018). DOI: 10.1186/s13059-018-1511-4