This article has been reviewed according to Science X's editorial process and policies. Editors have highlighted the following attributes while ensuring the content's credibility:
fact-checked
trusted source
proofread
Can computers speak for us?

In India, there's a popular saying among locals: "Kos-kos par badle paani, chaar kos par baani." The language spoken in India changes every few kilometers, just like the taste of the water.
Gopala Anumanchipalli, an assistant professor of electrical engineering and computer sciences at UC Berkeley, grew up in India, immersed in its lingual melting pot. As a young person, he became passionate about spoken words and, today, is fluent in five languages. He's now using that love of language, as well as his degree in engineering, to merge artificial intelligence, computer science and linguistics in order to give people with disease and disability a new way to talk.
"Right now, the time is right to completely reimagine assistive speaking technologies," says Anumanchipalli. "We have the scientific knowledge and technology at our disposal to help people who have lost the ability to verbally communicate and really improve their quality of life."
At the same time, the discoveries that Anumanchipalli has made along the way to developing these technologies—some of which are now in clinical trials—have also hinted at how to improve the speaking abilities of artificial intelligence platforms like Siri and Alexa, and diagnose and monitor speaking disorders in humans.
To reword the Indian aphorism, it might be said, The language spoken by computers changes every few years, just like our ability to understand human speech itself.
Opening a window into the human brain
When Anumanchipalli graduated from the International Institute of Information Technology in India with bachelor's and master's degrees in computer science, he was intrigued by how many human-like tasks computers were able to accomplish. But he saw one area they couldn't yet tackle.
"Computers were doing many interesting things, but spoken language was not quite solved. Computers couldn't speak like us," he says. "I thought this would be a really prime field for research."
So Anumanchipalli focused his graduate work on developing better artificial intelligence platforms for creating spoken words. He obtained a Ph.D. in Language and Information Technologies from Carnegie Mellon University and a Ph.D. in Electrical and Computer Engineering, from the Instituto Superior Técnico in Portugal.
He began to realize, however, that these artificial intelligence programs were limited by the lack of scientific knowledge on how the human brain processes and forms language—he was trying to mimic something that wasn't fully understood. So he began postdoctoral research with Edward Chang, a neurosurgeon at UCSF who studies the human brain's ability to develop speech, and how this ability goes awry with some diseases and disorders.
"When I was interviewing for this position, about 10 years ago, I remember having this conversation where I asked 'Will we ever be able to let someone speak again after they've lost their ability to speak?' It seemed like a real moonshot at the time," said Anumanchipalli.
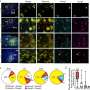
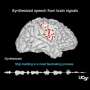
Together, Chang and Anumanchipalli began recording the brain activity of volunteers as they spoke. They began to discover patterns in the brain's electrical activity that let the researchers predict what someone was going to say before the words came out of their mouth. With that knowledge, they engineered a device that could generate speech based entirely on brain activity.
"The first time we heard speech directly from the brain was an amazing moment," says Anumanchipalli. "And then when we deployed this in patients who could no longer speak, it was incredibly rewarding and touching."
Today, that system is being tested in a small clinical trial of three people with full-body paralysis at UCSF.
Language at every level
In his own lab at Berkeley, Anumanchipalli remains immersed in nearly every aspect of the interface between language and computers.
"I'm interested in the entire pipeline of the spoken language system," he says. "There's the question of how we can create the next generation of devices that have human-like speech, but I'm also very driven by applications in medicine. How can we help people who have speech disorders?"
Today, he is developing a way for people with progressive diseases like ALS, who are slowly losing their speaking ability, to bank their voice. In the future, that will let them speak—using technology like the system Anumanchipalli developed at UCSF—with their own voice and personality rather than a generic, robotic voice.
He is also working on new ways of diagnosing and monitoring speech problems in children or people recovering from strokes. He envisions a system that might be able to track the speech of these people, predict whether they'll have speech problems in the future, or notify speech and language pathologists when their patients' speech improves or worsens in subtle ways.
Anumanchipalli thinks the time is ripe to begin pushing assistive speech technologies to new patients—even completely non-verbal individuals considered impossible cases in the past. There are millions of people, he says, who could benefit from the kinds of technologies he imagines are possible.
"There's this perception of people who can't talk as people who don't have the intellectual capacity to talk," he says. "In most cases, this isn't true and we want to use technology to change those perceptions and give everyone the ability to be perceived as their true self."