With two new methods, scientists hope to improve genome-wide association studies

As scientists probe and parse the genetic bases of what makes a human a human (or one human different from another), and vigorously push for greater use of whole genome sequencing, they find themselves increasingly threatened by the unthinkable: Too much data to make full sense of.
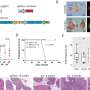
In a pair of papers published in the April 25, 2013 issue of PLOS Genetics, two diverse teams of scientists, both headed by researchers at the University of California, San Diego School of Medicine, describe novel statistical models that more broadly and deeply identify associations between bits of sequenced DNA called single nucleotide polymorphisms or SNPs and say lead to a more complete and accurate understanding of the genetic underpinnings of many diseases and how best to treat them.
"It's increasingly evident that highly heritable diseases and traits are influenced by a large number of genetic variants in different parts of the genome, each with small effects," said Anders M. Dale, PhD, a professor in the departments of Radiology, Neurosciences and Psychiatry at the UC San Diego School of Medicine. "Unfortunately, it's also increasingly evident that existing statistical methods, like genome-wide association studies (GWAS) that look for associations between SNPs and diseases, are severely underpowered and can't adequately incorporate all of this new, exciting and exceedingly rich data."
Dale cited, for example, a recent study published in Nature Genetics in which researchers used traditional GWAS to raise the number of SNPs associated with primary sclerosing cholangitis from four to 16. The scientists then applied the new statistical methods to identify 33 additional SNPs, more than tripling the number of genome locations associated with the life-threatening liver disease.
Generally speaking, the new methods boost researchers' analytical powers by incorporating a priori or prior knowledge about the function of SNPs with their pleiotrophic relationships to multiple phenotypes. Pleiotrophy occurs when one gene influences multiple sets of observed traits or phenotypes.
Dale and colleagues believe the new methods could lead to a paradigm shift in CWAS analysis, with profound implications across a broad range of complex traits and disorders.
"There is ever-greater emphasis being placed on expensive whole genome sequencing efforts," he said, "but as the science advances, the challenges become larger. The needle in the haystack of traditional GWAS involves searching through about one million SNPs. This will increase 10- to 100-fold, to about 3 billion positions. We think these new methodologies allow us to more completely exploit our resources, to extract the most information possible, which we think has important implications for gene discovery, drug development and more accurately assessing a person's overall genetic risk of developing a certain disease."
"All SNPs are not created equal: Genome-wide association studies reveal a consisten pattern of enrichment among functionally annotated SNPs." Authors include Andrew J. Schork, UCSD Cognitive Sciences Graduate Program, UCSD Center for Human Development and UCSD Multimodal Imaging Laboratory; Wesley K. Thompson and John R. Kelsoe, Department of Psychiatry, UCSD; Phillip Pham, Scripps Health, The Scripps Research Institute (TSRI); Ali Torkamani and Nicholas J. Schork, Scripps Health, TSRI; J. Cooper Roddy, UCSD Multimodal Laboratory; Patrick F. Sullivan, University of North Carolina; Michael C. O'Donovan, Cardiff University, United Kingdom; Helena Furberg, Memorial Sloan Kettering Cancer Center; The Tobacco and Genetics Consortium, The Bipolar Disorder Psychiatric Genomics Consortium, The Schizophrenic Psychiatric Genomics Consortium; and Ole A. Andreassen, UCSD Department of Psychiatry, University of Oslo and Oslo University Hospital.
"Improved detection of common variants associated with schizophrenia and bipolar disorder using pleiotropy-informed conditional False Discovery Rate."