June 3, 2014 report
Probing the limits to memory

(Medical Xpress)—There is no mystery in the way that computers store information. It is straightforward to determine how much memory they have and what is contained in that memory. Brains don't really have memory in this traditional sense. What they do have, are various adaptive systems that give the appearance of a limited computer-like memory as a side-effect of their primary functions. Two papers that recently appeared in PNAS describe the use of fMRI to explore the limits of human memory. In particular, they address roles of category and context in determining if something might be remembered, or forgotten.
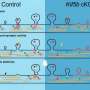
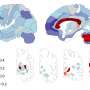
The first paper looked at memory performance when subjects were asked to remember several things at once. When the items to be recalled were from different categories—faces, bodies or other objects—the researchers found that the subjects did better. The scans revealed that the degree to which the mixed catagory recall was improved could be predicted by the degree to which the fMRI neural response patterns they obtained were also different.
The second study focused on recall performance when various objects appear in different contexts or scenes. Here the researchers found that when items don't appear in a context that is expected, the memory for that object is weakened. In this case it is hypothesized that the brain automatically prunes what it predetermines is an invlaid memory.
One major difference between our animal memory and say, Google's memory, is that while we constantly forget things, Google never does. On the other hand, while it is impossible for us to intentionally forget something on demand (at least while keeping everything else intact) Google could erase any specific memory it might so choose. Clearly in our case at least, all memories are not created equal. Despite that fact, we are neither jury nor judge of our own memories.
By it's own admission, in a typical search lasting 0.2 seconds Google consumes 0.3 Wh (roughly $0.0003 per search) for the whole job of indexing and retreiving the query. Based on the average adult requirement for 8000 kilojoules of food per day, Google concludes that a search is equivalent to the energy a person would burn in 10 seconds. If we take a simple task, for example the question, "Do you know X ?" what happens next inside our heads would put any Google search to shame.
The key thing in the two PNAS papers for us here is that category and context are not just incidentals of memory, they are memory. Without them there is no memory for us, and for Google, there is only a future of expontentiating storage requirements. Clearly there is more to life than text, audio, and video. The task ahead for computer engineers is to learn not just how to extract the outlines that define an image, but how to extract the outlines that define reality, and the events that occur within it.
If we are shown a face, as in the experiments done above, we can instaneously scan our whole history of existence to estimate whether we know it or not. We can also estimate whether we know their name within a few more micromoments. If the name is not recalled immediately, we would then attempt to summon it by creating additional context, quickly trying out sounds or images until one fits. Failing that, we can dig deeper into emotion and other meaningful contexts that draw forth how the face makes us feel, whether it might be someone favored or disfavored.
Failing all these efforts we might abandon hope at ever remembering the name. Only then we might paradoxically be given the perplexing experience of the name coming immediately to attention as another part of our brain that been earstwhile supressed in the effort had it there for us all along. If we are ever to build so-called memory implants that hope to do more good than harm, we will have to at least have an inkling as to how intact brains remember.
More information: 1. Processing multiple visual objects is limited by overlap in neural channels, Michael A. Cohen, PNAS, 2014. DOI: 10.1073/pnas.1317860111
2. Pruning of memories by context-based prediction error, Ghootae Kim, PNAS, 2014. DOI: 10.1073/pnas.1319438111
© 2014 Medical Xpress