In recognizing speech sounds, the brain does not work the way a computer does
How does the brain decide whether or not something is correct? When it comes to the processing of spoken language – particularly whether or not certain sound combinations are allowed in a language – the common theory has been that the brain applies a set of rules to determine whether combinations are permissible. Now the work of a Massachusetts General Hospital (MGH) investigator and his team supports a different explanation – that the brain decides whether or not a combination is allowable based on words that are already known. The findings may lead to better understanding of how brain processes are disrupted in stroke patients with aphasia and also address theories about the overall operation of the brain.
"Our findings have implications for the idea that the brain acts as a computer, which would mean that it uses rules – the equivalent of software commands – to manipulate information. Instead it looks like at least some of the processes that cognitive psychologists and linguists have historically attributed to the application of rules may instead emerge from the association of speech sounds with words we already know," says David Gow, PhD, of the MGH Department of Neurology.
"Recognizing words is tricky – we have different accents and different, individual vocal tracts; so the way individuals pronounce particular words always sounds a little different," he explains. "The fact that listeners almost always get those words right is really bizarre, and figuring out why that happens is an engineering problem. To address that, we borrowed a lot of ideas from other fields and people to create powerful new tools to investigate, not which parts of the brain are activated when we interpret spoken sounds, but how those areas interact."
Human beings speak more than 6,000 distinct language, and each language allows some ways to combine speech sounds into sequences but prohibits others. Although individuals are not usually conscious of these restrictions, native speakers have a strong sense of whether or not a combination is acceptable.
"Most English speakers could accept "doke" as a reasonable English word, but not "lgef," Gow explains. "When we hear a word that does not sound reasonable, we often mishear or repeat it in a way that makes it sound more acceptable. For example, the English language does not permit words that begin with the sounds "sr-," but that combination is allowed in several languages including Russian. As a result, most English speakers pronounce the Sanskrit word 'sri' – as in the name of the island nation Sri Lanka – as 'shri,' a combination of sounds found in English words like shriek and shred."
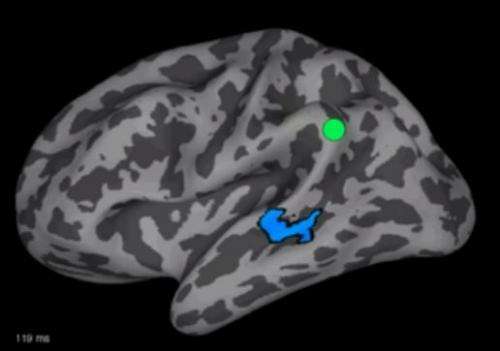
Gow's method of investigating how the human brain perceives and distinguishes among elements of spoken language combines electroencephalography (EEG), which records electrical brain activity; magnetoencephalograohy (MEG), which the measures subtle magnetic fields produced by brain activity, and magnetic resonance imaging (MRI), which reveals brain structure. Data gathered with those technologies are then analyzed using Granger causality, a method developed to determine cause-and-effect relationships among economic events, along with a Kalman filter, a procedure used to navigate missiles and spacecraft by predicting where something will be in the future. The results are "movies" of brain activity showing not only where and when activity occurs but also how signals move across the brain on a millisecond-by-millisecond level, information no other research team has produced.
In a paper published earlier this year in the online journal PLOS One, Gow and his co-author Conrad Nied, now a PhD candidate at the University of Washington, described their investigation of how the neural processes involved in the interpretation of sound combinations differ depending on whether or not a combination would be permitted in the English language. Their goal was determining which of three potential mechanisms are actually involved in the way humans "repair" nonpermissible sound combinations – the application of rules regarding sound combinations, the frequency with which particular combinations have been encountered, or whether sound combinations occur in known words.
The study enrolled 10 adult American English speakers who listened to a series of recordings of spoken nonsense syllables that began with sounds ranging between "s" to "shl" – a combination not found at the beginning of English words – and indicated by means of a button push whether they heard an initial "s" or "sh." EEG and MEG readings were taken during the task, and the results were projected onto MR images taken separately. Analysis focused on 22 regions of interest where brain activation increased during the task, with particular attention to those regions' interactions with an area previously shown to play a role in identifying speech sounds.
While the results revealed complex patterns of interaction between the measured regions, the areas that had the greatest effect on regions that identify speech sounds were regions involved in the representation of words, not those responsible for rules. "We found that it's the areas of the brain involved in representing the sound of words, not sounds in isolation or abstract rules, that send back the important information. And the interesting thing is that the words you know give you the rules to follow. You want to put sounds together in a way that's easy for you to hear and to figure out what the other person is saying," explains Gow, who is a clinical instructor in Neurology at Harvard Medical School and a professor of Psychology at Salem State University.
Gow and his team are planning to investigate the same mechanisms in stroke patients who have trouble producing words, with the goal of understanding how language processing breaks down and perhaps may be restored, as well as to look at whether learning words with previously nonpermissible combinations changes activation in the brains of healthy volunteers. The study reported in the PLOS One paper was supported by National Institute of Deafness and Communicative Disorders grant R01 DC003108.