Cancer gene dependency maps help reveal proteins' relationships

By merging cancer functional genetic data with information on protein interactions, scientists can explore protein complexes at massive scale.
"Dependency" mapping reveals the genetic adaptations cancer cells make to survive. And while this approach is helping identify promising treatment strategies for several cancer types, researchers have now found that it also provides an opportunity to probe the intricacies of protein interactions.
While sequencing efforts have likely identified nearly all genes involved in cancer, studies of those genes' protein products and how they interact have been much more difficult. Because proteins work together to drive the lion's share of cellular activities, the ability to explore those interactions at scale could provide insight into all manner of biological processes.
Reporting in Cell Systems, a team led at the Broad by graduate student Joshua Pan, computational biologist Robin Meyers, Cancer Data Science group associate director Aviad Tsherniak, and institute member and Epigenomics Program co-director Cigall Kadoch of the Dana-Farber Cancer Institute, describe how by combining genome-scale dependency data from the Broad Cancer Program's Dependency Map (DepMap) project with large, existing protein interaction datasets, they created a framework for examining protein complexes (assemblies of proteins that carry out coordinated tasks, such as gene transcription).
The team's underlying hypothesis was that:
- When a gene is knocked out (with CRISPR) or silenced (with RNA interference), the cell can no longer make that gene's protein product. The cell's functional state or survival (it's "fitness") changes as a result.
- Two proteins whose losses have similar fitness effects likely perform similar functions, and may even be members of the same protein complex.
- By profiling in pooled screens how all these knock-outs affect cell fitness, and comparing those profiles across hundreds of cancer cell lines, researchers can group proteins by functions and interactions, probe the roles of known protein complex members, and highlight previously unrecognized ones.
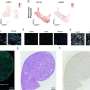
The DepMap dataset, which included CRISPR data on 342 cancer cell lines and RNAi data on 501, provided a perfect starting point. Integrating these data with those from seven recent protein interaction datasets, the team developed computer models that scored and grouped the components of hundreds of human protein complexes based on their effects on cell fitness. Those fitness groupings fell into patterns aligning with the proteins' functions and biochemical relationships.
Benchmarked against well-studied complexes, the team's models accurately captured known lists of component proteins in their makeup, modular hierarchy, and even structural relationships. The models also pointed out subunits shared between different, functionally distinct complexes, and identified previously unrecognized components of a complex called SWI/SNF or BAF (members of which are often mutated in cancer).
The researchers think their models will only increase in power as new fitness or dependency data from additional cell lines become available, and could help illuminate the effects disease-associated genetic variants or structural changes have on protein interactions and disease biology.
More information: Joshua Pan et al. Interrogation of Mammalian Protein Complex Structure, Function, and Membership Using Genome-Scale Fitness Screens, Cell Systems (2018). DOI: 10.1016/j.cels.2018.04.011