Genomic study brings us closer to precision medicine for type 2 diabetes

Most patients diagnosed with type 2 diabetes are treated with a "one-size-fits-all" protocol that is not tailored to each person's physiology and may leave many cases inadequately managed. A new study by scientists at the Broad Institute of MIT and Harvard and Massachusetts General Hospital (MGH) indicates that inherited genetic changes may underlie the variability observed among patients in the clinic, with several pathophysiological processes potentially leading to high blood sugar and its resulting consequences.
By analyzing genomic data with a computational tool that incorporates genetic complexity, the researchers identified five distinct groups of DNA sites that appear to drive distinct forms of the illness in unique ways.
The work represents a first step toward using genetics to identify subtypes of type 2 diabetes, which could help physicians prescribe interventions aimed at the cause of the disease, rather than just the symptoms.
The study appears in PLOS Medicine.
"When treating type 2 diabetes, we have a dozen or so medications we can use, but after you start someone on the standard algorithm, it's primarily trial and error," said senior author Jose Florez, an endocrinologist at MGH, co-director of the Broad's Metabolism Program, and professor at Harvard Medical School. "We need a more granular approach that addresses the many different molecular processes leading to high blood sugar."
It's known that type 2 diabetes can be broadly grouped into cases driven either by the inability of pancreatic beta cells to make enough insulin, known as insulin deficiency, or by the inability of liver, muscle or fat tissues to use insulin properly, known as insulin resistance.
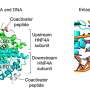
Previous research attempted to define more subtypes of type 2 diabetes based on indicators such as beta-cell function, insulin resistance, or body-mass index, but those traits can vary greatly through life and during the course of disease. Inherited genetic differences are present at birth, and so a more reliable method would be to create subtypes based on DNA variations that have been associated with diabetes risk in large-scale genetic studies. These variations can be grouped into clusters based on how they impact diabetes-related traits; for example, genetic changes linked to high triglyceride levels are likely to work through the same biological processes.
Early efforts to do so used a "hard-clustering" approach, in which each genetic variation was assigned to only one cluster. However, this failed to produce patterns that made biological sense.
Miriam Udler, an endocrinologist at MGH and postdoctoral researcher in the Florez lab, took another approach. She teamed up with Gaddy Getz and Jaegil Kim of the Broad's Cancer Genomics team to apply a "soft-clustering" approach known as Bayesian non-negative matrix factorization, which allows each variant to fall into more than one cluster.
"The soft-clustering method is better for studying complex diseases, in which disease-related genetic sites may regulate not just one gene or process, but several," said Udler.
The new work revealed five clusters of genetic variants distinguished by distinct underlying cellular processes, within the existing major divisions of insulin-resistant and insulin-deficient disease. Two of these clusters contain variants that suggest beta cells aren't working properly, but that differ in their impacts on levels of the insulin precursor, proinsulin. The other three clusters contain DNA variants related to insulin resistance, including one cluster mediated by obesity, one defined by disrupted metabolism of fats in the liver, and one driven by defects in the distribution of fat within the body, known as lipodystrophy.
To confirm these observations, the team analyzed data from the National Institutes of Health's Roadmap Epigenomics Project, a public resource of epigenomic data for biology and disease research. They found that the genes contained in the clusters were more active in the tissue types one would expect.
To further test whether each cluster had been assigned the correct biological mechanism, the researchers gathered data from four independent cohorts of patients with type 2 diabetes and first calculated the patients' individual genetic risk scores for each cluster. They found nearly a third of patients scored highly for only one predominant cluster, suggesting that their diabetes may be driven predominantly by a single biological mechanism.
When they next analyzed measurements of diabetes-related traits from high-scoring subjects, they saw patterns that strongly reflected the suspected biological mechanism and distinguished them from all other patients with type 2 diabetes—for example, patients who fell into the obesity-mediated cluster were indeed found to have increased body-mass index and body fat percentage.
The results appear to reflect some of the diversity observed by endocrinologists in the clinic. For example, people who scored high on the lipodystrophy-like cluster were likely to be thinner than average but have insulin-resistant diabetes, similar to a rare type of diabetes in which fat accumulates in the liver, which is a fundamentally different process from insulin resistance that results from obesity.
"The clusters from our study seem to recapitulate what we observe in clinical practice," said Florez. "Now we need to determine whether these clusters translate to differences in disease progression, complications, and response to treatment."
In addition to paving the way to clinically useful subtypes, the work sheds light on the diverse pathophysiology underlying type 2 diabetes and offers a model for unraveling the heterogeneity of other complex diseases.
"This study has given us the most comprehensive view to date of the genetic pathways underlying a common illness, which if not adequately treated can lead to devastating complications," said Udler. "We're excited to see how our approach can help researchers make steps towards precision medicine for other illnesses as well."
More information: Udler MS, et al. Type 2 diabetes genetic loci informed by multi-trait associations point to disease mechanisms and subtypes: A soft clustering analysis. PLOS Medicine. Online September 21, 2018. DOI: 10.1371/journal.pmed.1002654